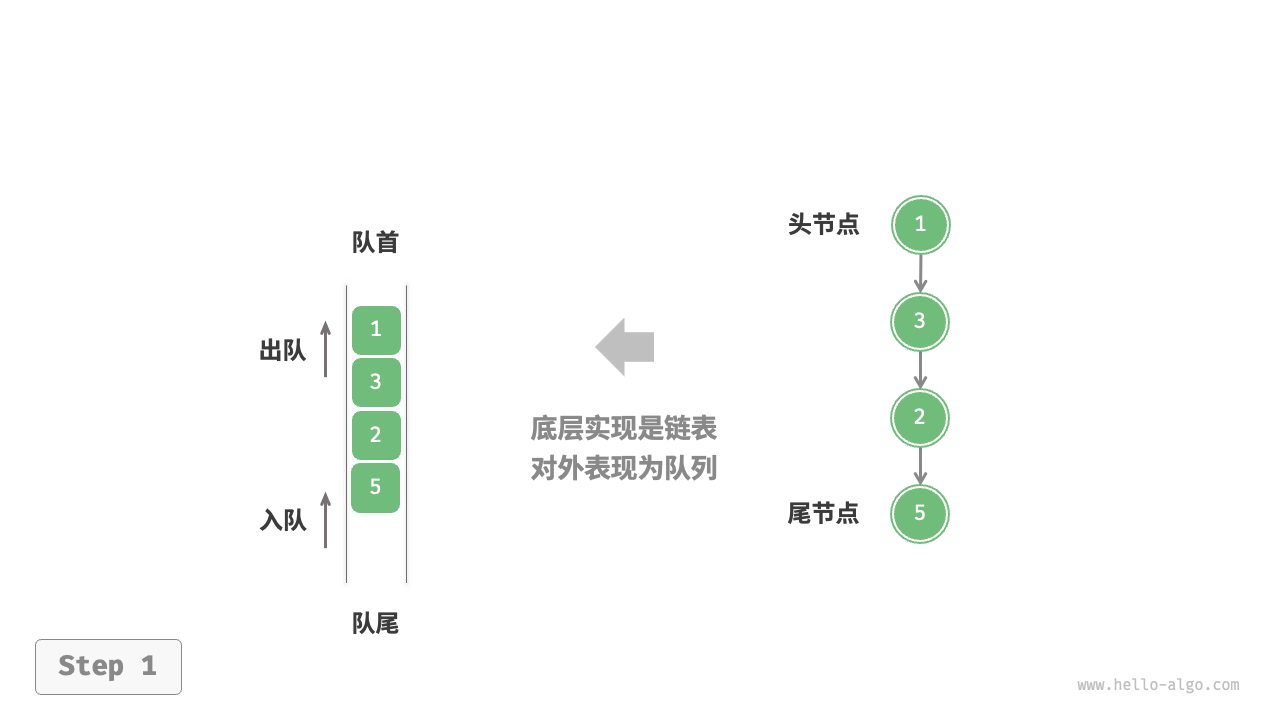
# 访问 defaccess(head: ListNode, index: int) -> ListNode | None: ifnot head: returnNone for _ in range(index): head = head.next return head
# print(access(n0, 2).val)
# 查找 deffind(head: ListNode, val: int) -> int: """在链表中查找值为 target 的首个节点""" index = 0 while head: if head.val == val: return index else: index += 1 head = head.next return-1
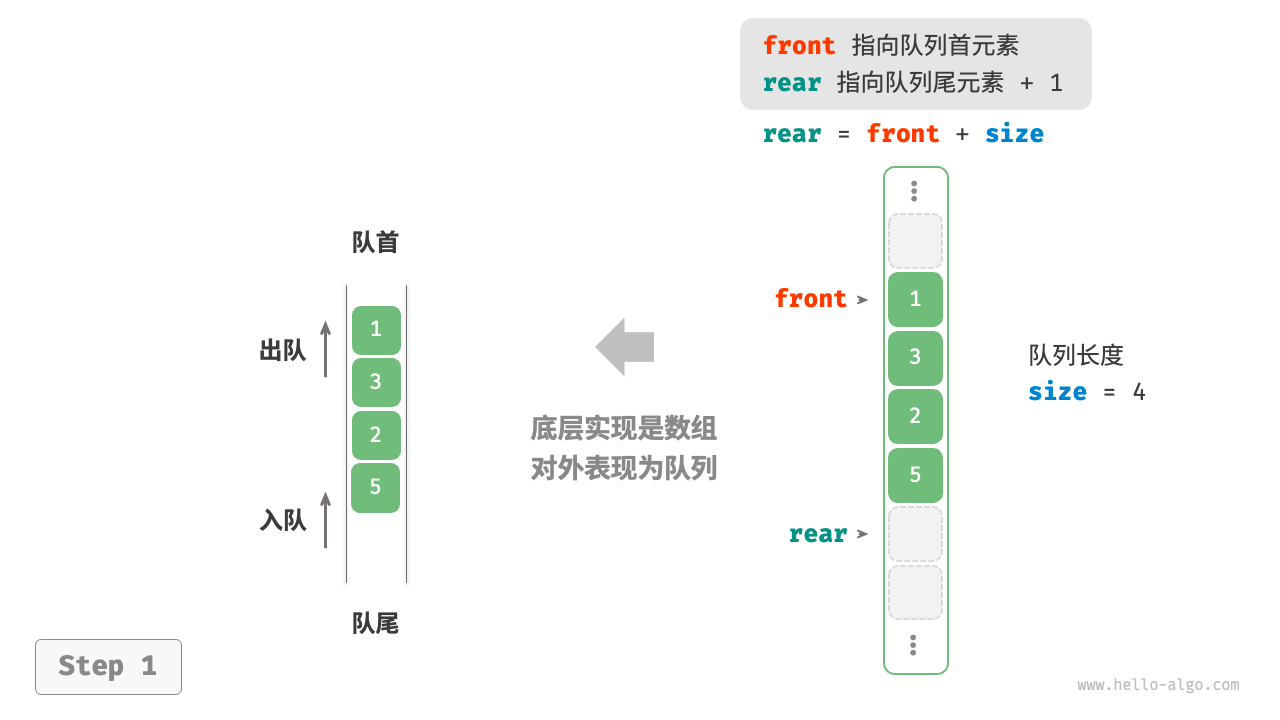
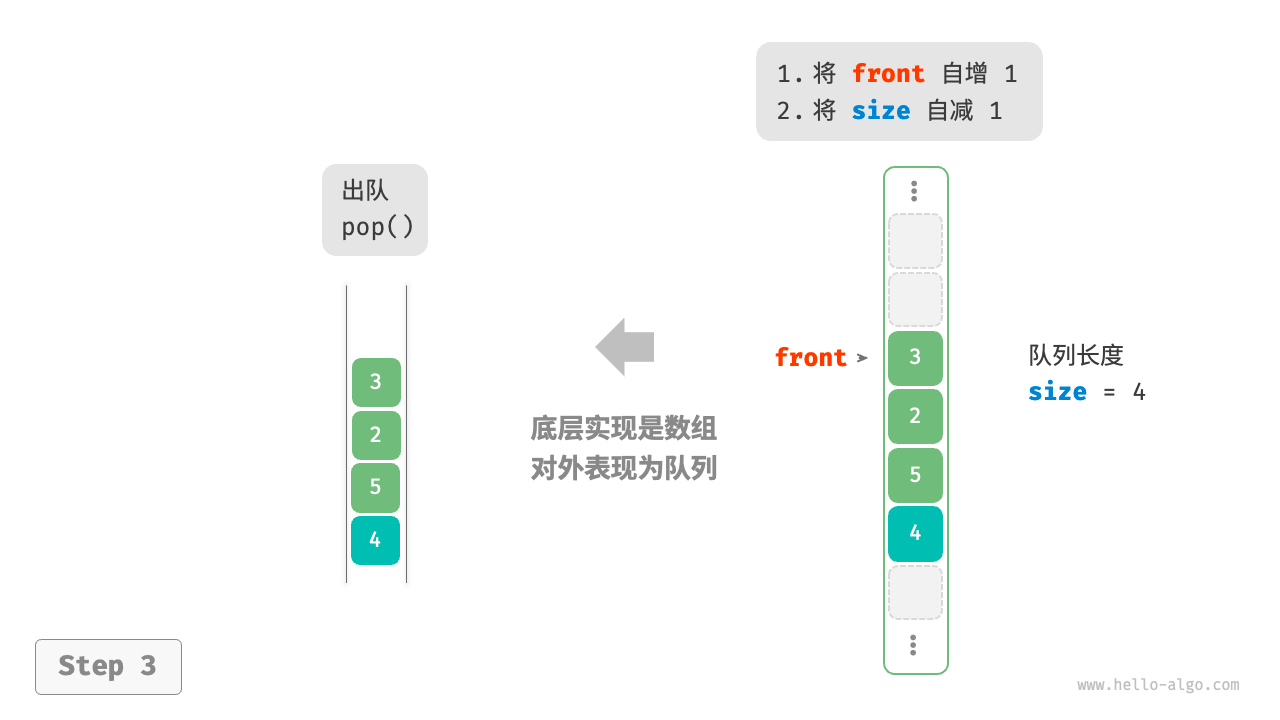
defpeek(self): if self.is_empty(): raise IndexError("队列为空") return self._nums[self._front]
defto_list(self) -> list[int]: """返回列表用于打印""" res = [0] * self.size() j: int = self._front for i in range(self.size()): res[i] = self._nums[(j % self.capacity())] j += 1 return res
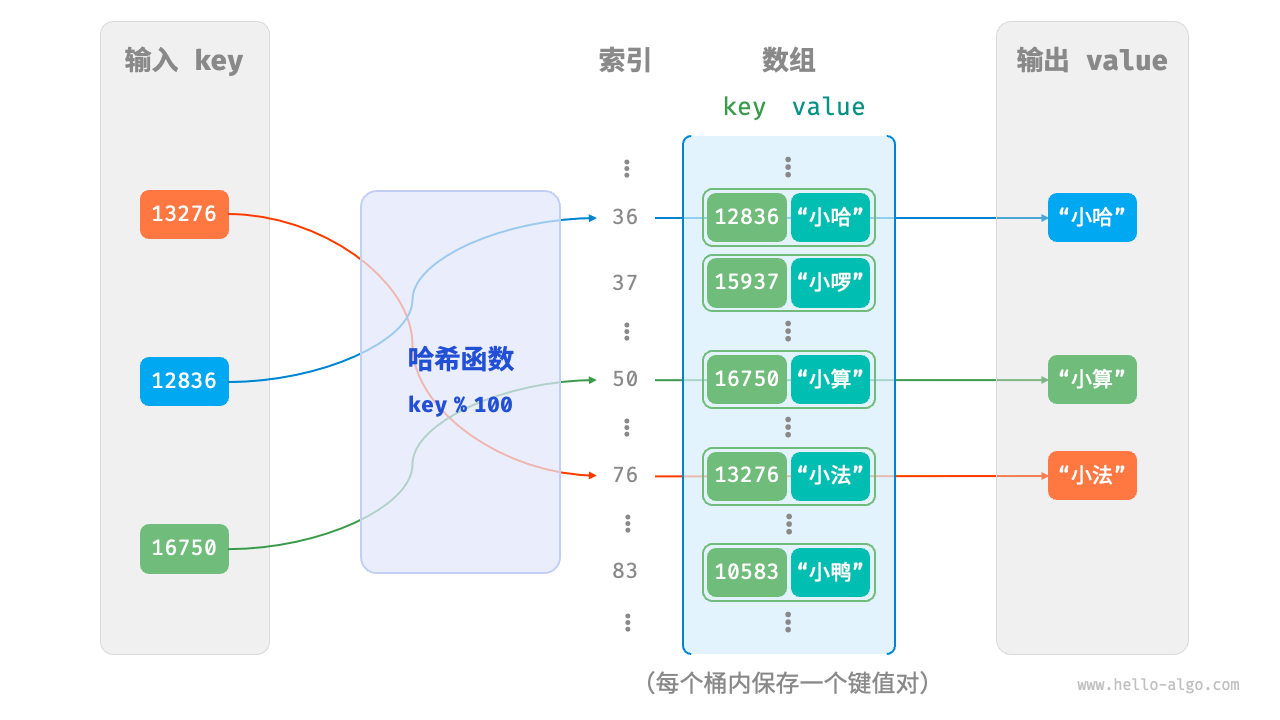
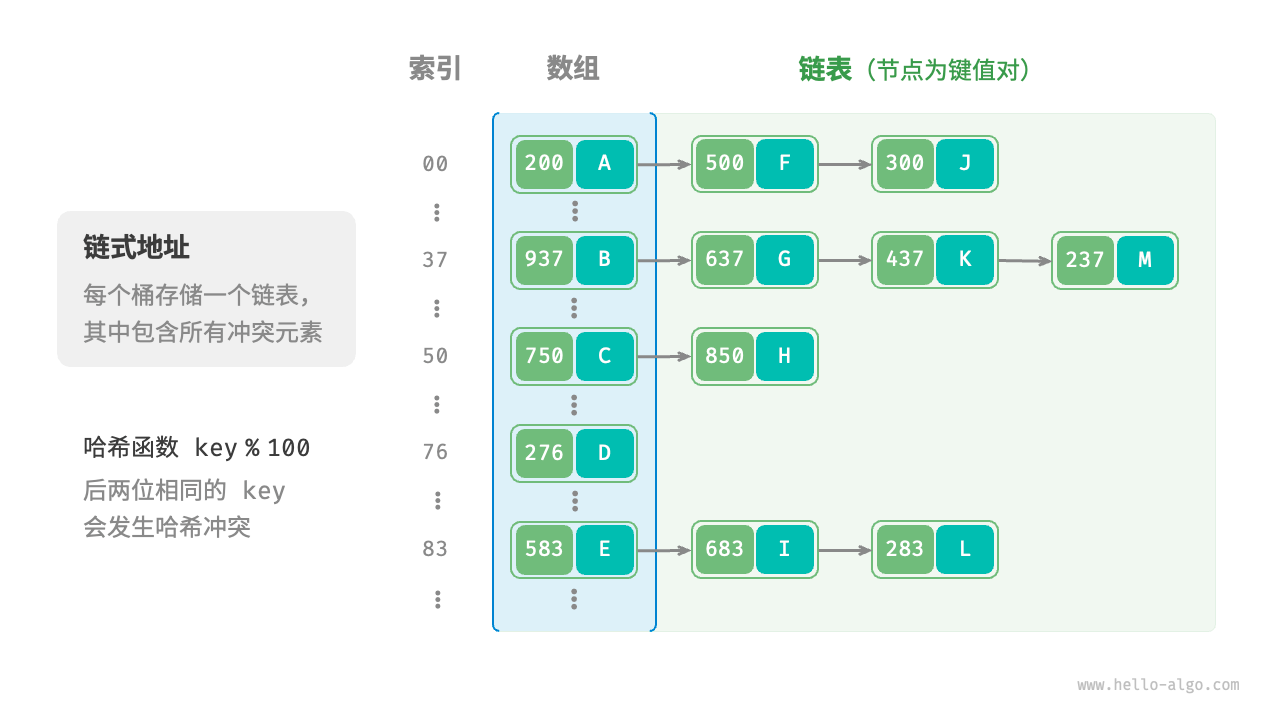
defget(self, key): index = self.hash_func(key) bucket = self.buckets[index] for pair in bucket: if pair.key == key: return pair.val returnNone
defput(self, key, val): """添加操作""" # 当负载因子超过阈值时,执行扩容 if self.load_factor() > self.load_thres: self.extend() index = self.hash_func(key) bucket = self.buckets[index] # 遍历桶,若遇到指定 key ,则更新对应 val 并返回 for pair in bucket: if pair.key == key: pair.val = val return # 若无该 key ,则将键值对添加至尾部 pair = Pair(key, val) bucket.append(pair) self.size += 1
defremove(self, key): index = self.hash_func(key) bucket = self.buckets[index] for pair in bucket: if pair.key == key: bucket.remove(pair) self.size -= 1 break
defextend(self): """扩容哈希表""" # 暂存原哈希表 buckets = self.buckets self.capacity *= self.extend_ratio self.buckets = [[] for _ in range(self.capacity)] # 将键值对从原哈希表搬运至新哈希表 for bucket in buckets: for pair in bucket: self.put(pair.key, pair.val)
defprint(self): """打印哈希表""" for bucket in self.buckets: res = [] for pair in bucket: res.append(str(pair.key) + " -> " + pair.val) print(res)
defval(self, i: int) -> int | None: """获取索引为 i 节点的值""" # 若索引越界,则返回 None ,代表空位 if i < 0or i >= self.size(): returnNone return self._tree[i]
defleft(self, i: int) -> int | None: """获取索引为 i 节点的左子节点的索引""" return2 * i + 1
defright(self, i: int) -> int | None: """获取索引为 i 节点的右子节点的索引""" return2 * i + 2
defparent(self, i: int) -> int | None: """获取索引为 i 节点的父节点的索引""" return (i - 1) // 2
deflevel_order(self) -> list[int]: """层序遍历""" self.res = [] # 直接遍历数组 for i in range(self.size()): if self.val(i) isnotNone: self.res.append(self.val(i)) return self.res
defdfs(self, i: int, order: str): """深度优先遍历""" if self.val(i) isNone: return # 前序遍历 if order == "pre": self.res.append(self.val(i)) self.dfs(self.left(i), order) # 中序遍历 if order == "in": self.res.append(self.val(i)) self.dfs(self.right(i), order) # 后序遍历 if order == "post": self.res.append(self.val(i))
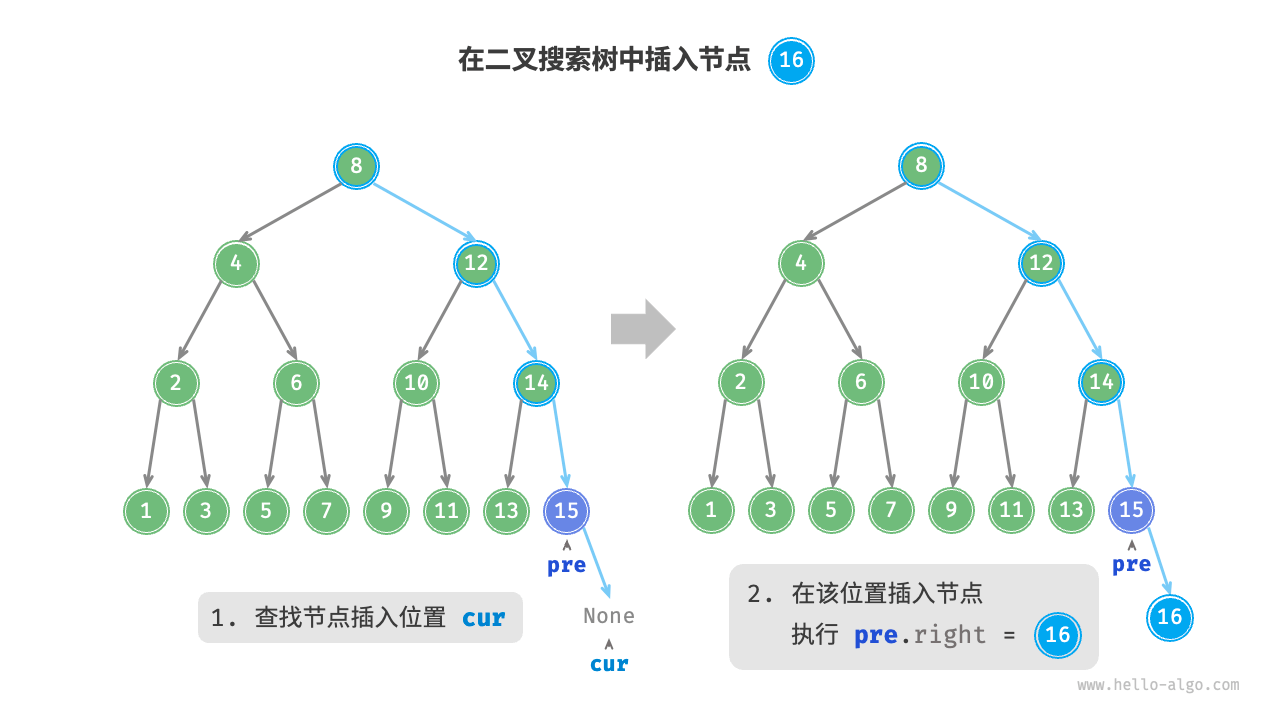
cur, pre = root, None while cur isnotNone: # 找到重复节点,直接返回 if cur.val == num: return pre = cur if cur.val < num: cur = cur.right else: cur = cur.left # 插入节点 node = TreeNode(num) if pre.val < num: pre.right = node else: pre.left = node
defremove(self, num: int): """删除节点""" # 若树为空,直接提前返回 if self._root isNone: return # 循环查找,越过叶节点后跳出 cur, pre = self._root, None while cur isnotNone: # 找到待删除节点,跳出循环 if cur.val == num: break pre = cur # 待删除节点在 cur 的右子树中 if cur.val < num: cur = cur.right # 待删除节点在 cur 的左子树中 else: cur = cur.left # 若无待删除节点,则直接返回 if cur isNone: return
# 子节点数量 = 0 or 1 if cur.left isNoneor cur.right isNone: # 当子节点数量 = 0 / 1 时, child = null / 该子节点 child = cur.left or cur.right # 删除节点 cur if cur != self._root: if pre.left == cur: pre.left = child else: pre.right = child else: # 若删除节点为根节点,则重新指定根节点 self._root = child # 子节点数量 = 2 else: # 获取中序遍历中 cur 的下一个节点 tmp: TreeNode = cur.right while tmp.left isnotNone: tmp = tmp.left # 递归删除节点 tmp self.remove(tmp.val) # 用 tmp 覆盖 cur cur.val = tmp.val
defsift_up(self, i): """从节点 i 开始,从底至顶堆化""" whileTrue: p_index = self.parent(i) # 当“越过根节点”或“节点无须修复”时,结束堆化 if p_index < 0or self.max_heap[i] <= self.max_heap[p_index]: break # 交换两节点 self.swap(i, p_index) # 循环向上堆化 i = p_index
defpop(self): if self.is_empty(): raise IndexError("堆为空") # 交换根节点和最后一个节点 self.swap(0, self.size() - 1) # 删除最后一个节点 val = self.max_heap.pop() # 从顶至下进行堆化 self.sift_down(0) return val
defsift_down(self, i: int): """从节点 i 开始,从顶至底堆化""" whileTrue: # 判断节点 i, l, r 中值最大的节点,记为 ma l_index, r_index, max_index = self.left(i), self.right(i), i if l_index < self.size() and self.max_heap[l_index] > self.max_heap[max_index]: max_index = l_index if r_index < self.size() and self.max_heap[r_index] > self.max_heap[max_index]: max_index = r_index # 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出 if max_index == i: break # 交换两节点 self.swap(i, max_index) # 循环向下堆化 i = max_index
2.Top-k 问题
初始化一个小顶堆,其堆顶元素最小。
先将数组的前 𝑘 个元素依次入堆。
从第 𝑘+1 个元素开始,若当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆(并堆化)。
遍历完成后,堆中保存的就是最大的 𝑘 个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
deftop_k_heap(nums: list[int], k: int) -> list[int]: """基于堆查找数组中最大的 k 个元素""" # 初始化小顶堆 heap = [] # 将数组的前 k 个元素入堆 for i in range(k): heapq.heappush(heap, nums[i]) # 从第 k+1 个元素开始,保持堆的长度为 k for i in range(k, len(nums)): # 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆 if nums[i] > heap[0]: heapq.heappop(heap) heapq.heappush(heap, nums[i]) return heap
defadd_vertex(self, val): n = self.size() self.vertices.append(val) new_row = [0] * n # 添加行 self.adj_mat.append(new_row) # 添加列 for row in self.adj_mat: row.append(0)
defremove_vertex(self, index): if index > self.size(): raise IndexError self.vertices.pop(index) self.adj_mat.pop(index) for row in self.adj_mat: row.pop(index)
defadd_edge(self, i, j): # 索引越界与相等处理 if i < 0or j < 0or i > self.size() or j > self.size() or i == j: raise IndexError # 在无向图中,邻接矩阵关于主对角线对称,即满足 (i, j) == (j, i) self.adj_mat[i][j] = 1 self.adj_mat[j][i] = 1
defremove_edge(self, i, j): # 索引越界与相等处理 if i < 0or j < 0or i > self.size() or j > self.size() or i == j: raise IndexError # 在无向图中,邻接矩阵关于主对角线对称,即满足 (i, j) == (j, i) self.adj_mat[i][j] = 0 self.adj_mat[j][i] = 0
def__init__(self, edges: list[list[Vertex]]): self.adj_dict = dict[Vertex, list[Vertex]]() for edge in edges: self.add_vertex(edge[0]) self.add_vertex(edge[1]) self.add_edge(edge[0], edge[1])
defsize(self): return len(self.adj_dict)
defadd_vertex(self, vet: Vertex): if vet in self.adj_dict: return self.adj_dict[vet] = []
defremove_vertex(self, vet: Vertex): if vet notin self.adj_dict: raise ValueError self.adj_dict.pop(vet) for key in self.adj_dict: edge_list = self.adj_dict[key] if vet in edge_list: edge_list.remove(vet)
defadd_edge(self, vet1: Vertex, vet2: Vertex): if vet1 notin self.adj_dict or vet2 notin self.adj_dict or vet1 == vet2: raise ValueError() self.adj_dict[vet1].append(vet2) self.adj_dict[vet2].append(vet1)
defremove_edge(self, vet1: Vertex, vet2: Vertex): if vet1 notin self.adj_dict or vet2 notin self.adj_dict or vet1 == vet2: raise ValueError() self.adj_dict[vet1].remove(vet2) self.adj_dict[vet2].remove(vet1)
defprint(self): """打印邻接表""" print("邻接表 =") for vertex in self.adj_dict: tmp = [v.val for v in self.adj_dict[vertex]] print(f"{vertex.val}: {tmp},")
from graph_adjacency_list import Vertex, GraphAdjList from collections import deque
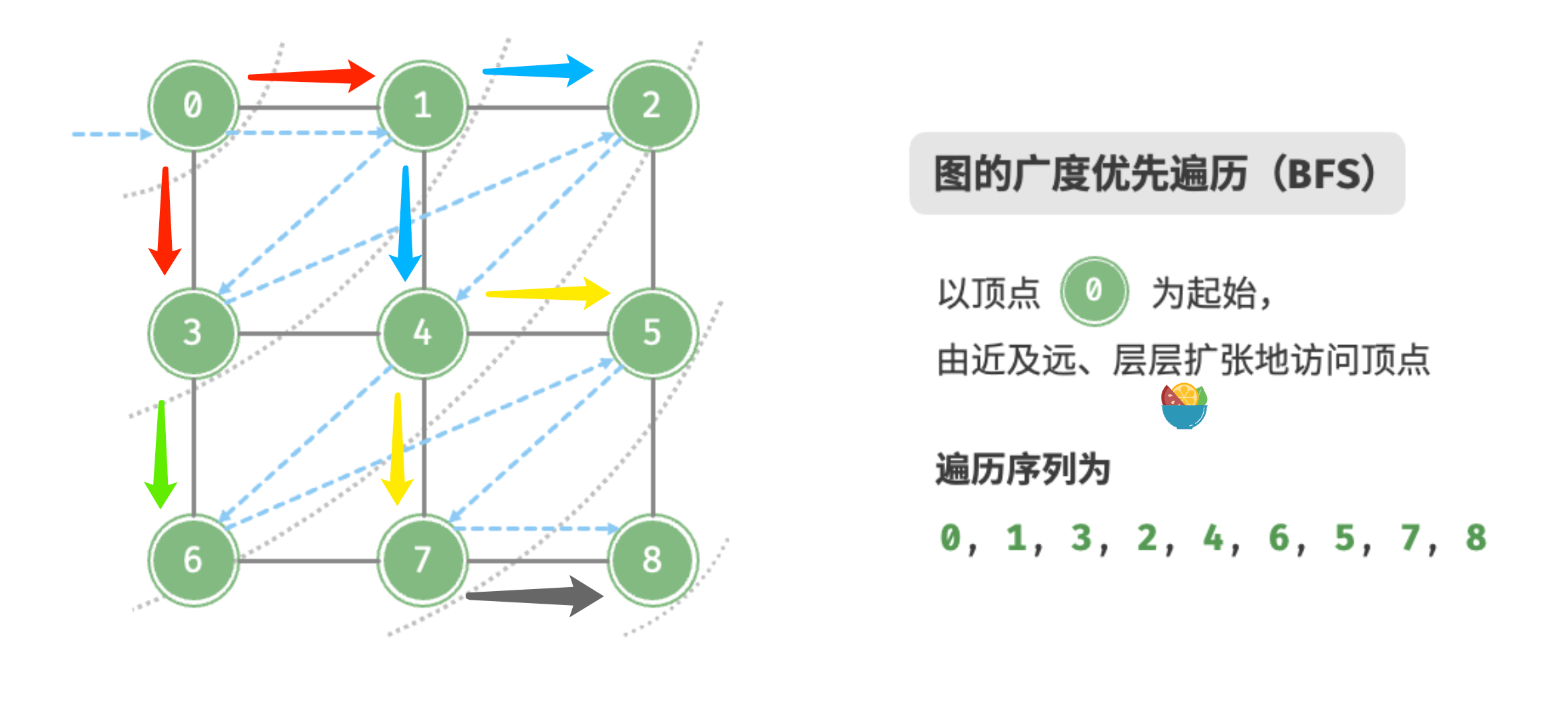
defgraph_bfs(graph: GraphAdjList, start_vet: Vertex) -> list[Vertex]: """广度优先遍历""" # 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点 # 顶点遍历序列 res = [] # 哈希集合,用于记录已被访问过的顶点 visited = set[Vertex]([start_vet]) que = deque[Vertex]([start_vet]) # 以顶点 vet 为起点,循环直至访问完所有顶点 while len(que) > 0: vet = que.popleft() res.append(vet) vet_list = graph.adj_dict[vet] for v in vet_list: if v in visited: continue visited.add(v) que.append(v) return res
from graph_adjacency_list import Vertex, GraphAdjList
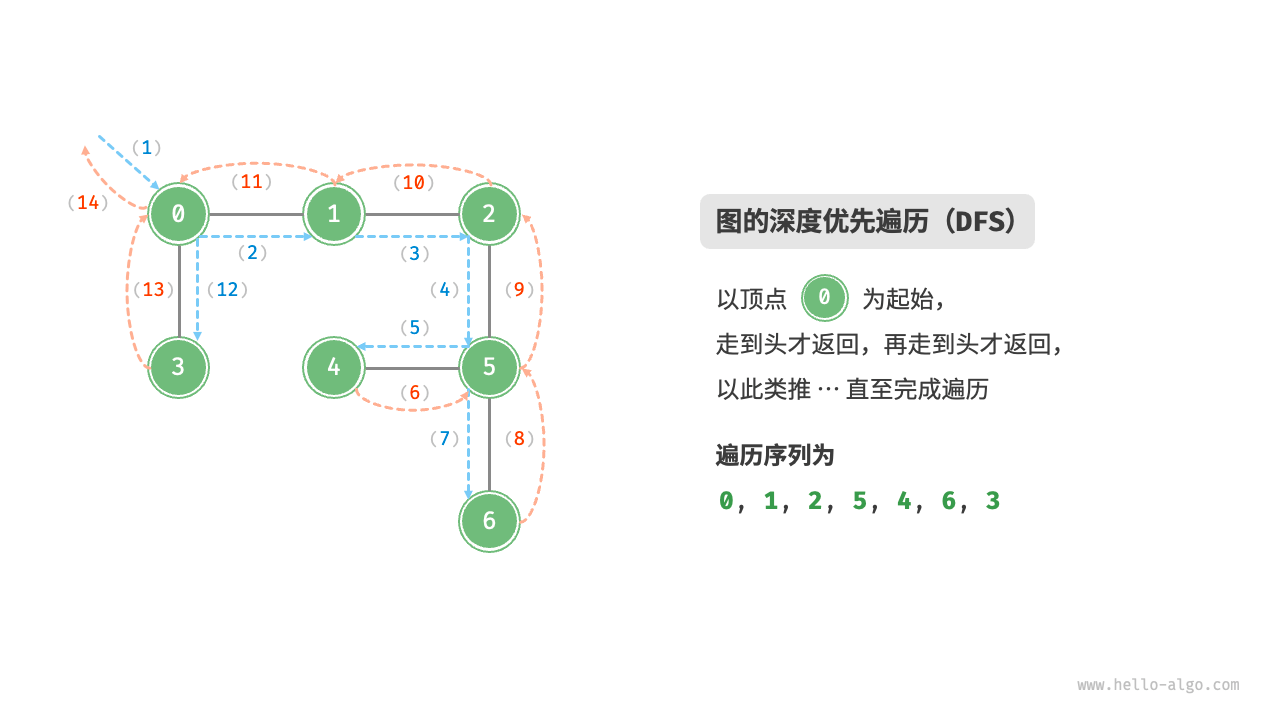
defdfs(graph: GraphAdjList, visited: set[Vertex], res: list[Vertex], vet: Vertex): """深度优先遍历辅助函数""" res.append(vet) visited.add(vet) vet_list = graph.adj_dict[vet] for v in vet_list: if v in visited: continue dfs(graph, visited, res, v)
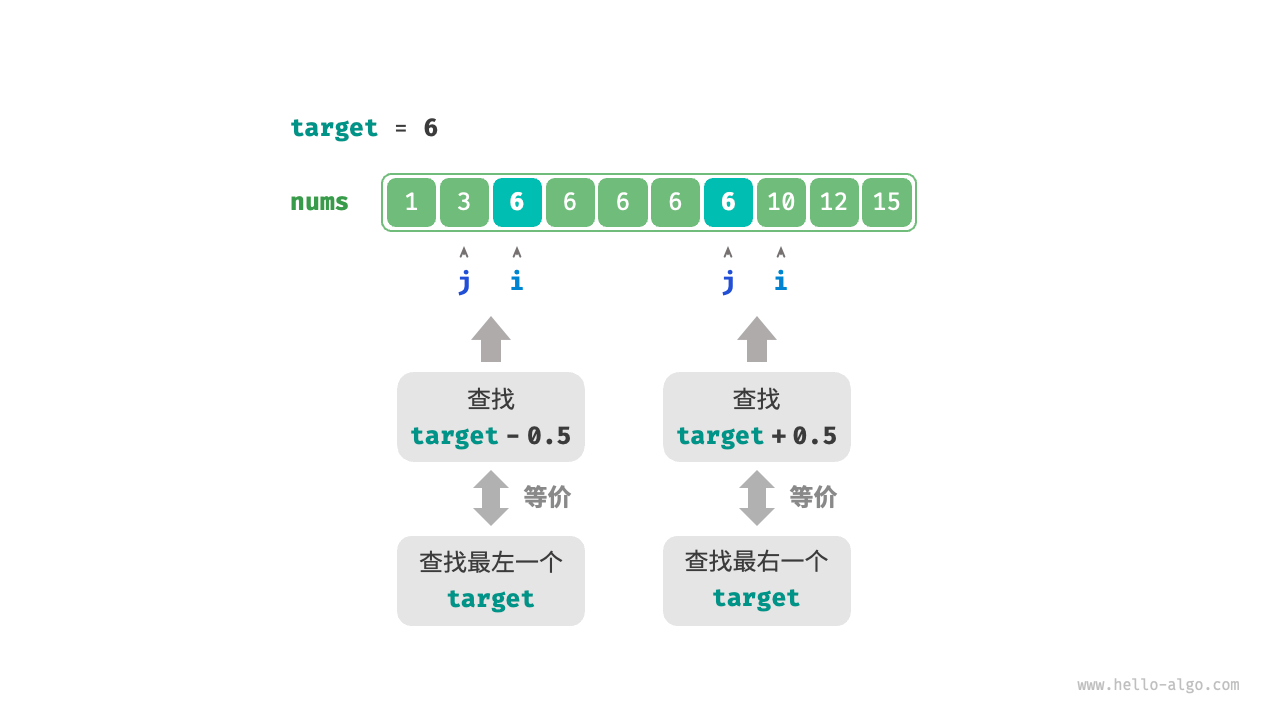
defbinary_search_common(nums: list[int], target): i, j = 0, len(nums) - 1 while i <= j: m = (i + j) // 2 if nums[m] < target: i = m + 1 elif nums[m] > target: j = m - 1 else: j = m - 1# 首个小于 target 的元素在区间 [i, m-1] 中 return j, i
deffind_num_left_or_index(nums, target): j, i = binary_search_common(nums, target) if nums[i] != target: return-1 return nums[i]
deffind_num_right(nums, target): j, i = binary_search_common(nums, target) if nums[j] != target - 0.5: return-1 return nums[j]
defprime_factors(n): factors = [] # 处理2的因子 while n % 2 == 0: factors.append(2) n //= 2 # 处理3及以上的因子 for i in range(3, int(n ** 0.5) + 1, 2): while n % i == 0: factors.append(i) n //= i # 如果n本身是质数且大于2 if n > 2: factors.append(n) return factors
# 输入一个正整数 number = int(input("请输入一个正整数: ")) # 获取并输出所有质因子 result = prime_factors(number) print("质因子从小到大的顺序为:", " ".join(map(str, result)))