在上一篇《启用 WebGPU 加速 Web 端模型推理》中提到“可以将 tensorflow.js 和现代化的前端框架结合”,基于这个想法,我继续展开迭代,将代码迁移到 Next.js 14 框架中,并针对模型在浏览器端遇到的一些加载和推理问题,进行了一番优化,整个过程大致包含如下步骤:
将 tensorflow.js 与 Next.js 整合
基于 IndexedDB 的模型文件缓存
针对 webgl backend 的内存管理
针对 webgl backend 的模型 warm up
基于 webgl backend 的推理速度对比
一、与 Next.js 的整合
使用的版本:Next.js 14.2.3,Tensorflow.js 4.18.0
这部分其实是比较简单的,主要是将原本的vanilla js转换成react代码,因为绝大部分代码都需要跑在client side,所以并不涉及RSC,加之原始代码量也不多,所以没花多少功夫。值得留意的一点是web worker在Next.js中的写法略有不同,代码如下:
1 | // page.tsx |
1 | // worker.ts |
二、使用 IndexedDB
1.缓存模型文件
IndexedDB 是一种浏览器内建的数据库,拥有比 localStorage 大得多的容量,还支持索引和事务,可用于离线数据的存储,并且浏览器的支持度也不错:

因为模型文件通常比较大,使用 IndexedDB 缓存到客户端,可以有效提升页面二次加载的速度。
tensorflow.js 的model.save方法支持传入一个 IndexedDB url,会自动将下载的模型文件储存到客户端的IndexedDB中,然后可以通过loadGraphModel加载刚才的 IndexedDB url来初始化模型,代码如下:
1 | const IDB_URL = "indexeddb://rps-model"; |
保存后的模型数据如下图:tensorflowjs相当于一个db,其中包含2个table(model_info_store和models_store)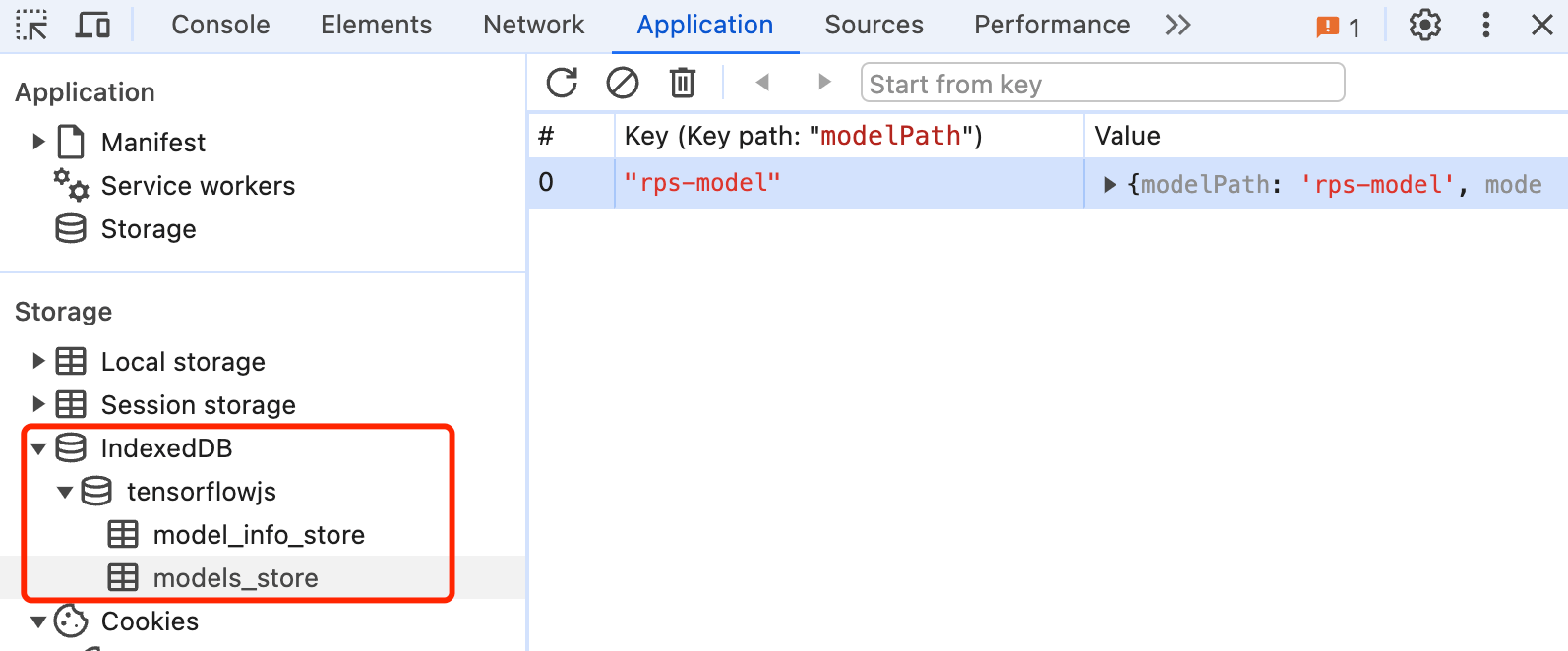
之后就可以通过如下代码,来判断本地是否已经保存了模型,从而避免重复下载
1 | const modelInfo = await tf.io.listModels(); // 列出客户端已经保存的模型 |
2.更新模型文件
在缓存了模型文件后,很自然的会想到一个问题:后续该如何更新呢?
由于我的线上模型文件存储在AWS S3桶中,这里采用的策略是:通过比对本地模型的saved time和线上模型的lastUpdate time来判断是否更新,当然更严谨的方式,我觉得还是应该使用version来控制。使用saved time的好处是,tf在保存模型时自动会添加这个字段,不需要手动操作了。
对于从S3桶中获取lastUpdate time,考虑到当前请求是无状态的,其实是有几种方式可以选择的:
- next.js client side -> S3
- next.js server side -> S3 -> client side
- backend -> S3 -> client side
最终我选择了第3种,原因如下:
- 如果选择第1种方式,势必需要在client端加载s3-sdk,以及配置访问密钥等,相对来说不够安全,而且,我也不想把client搞的太重
- 如果选择第2种方式,后续如果请求要改为有状态的(比如鉴权)会有点麻烦
- 因为之前在AWS EC2上用Django构建了一个后端服务,集成了S3的访问,所以这里直接加个接口会更方便
具体实现如下:
Django添加的查询lastUpdateTime接口:
1 | def get_model_last_update_time(model_name, config_file='model.json'): |
client side拿到lastUpdateTime后进行比对
1 | async function isModelLatest(dateSaved: Date) { |
这样当线上模型更新后,本地也能拉取到,唯一不好的是多了一次请求
三、启用 webgl backend
1.Next.js + tf wasm backend的问题
这里也算是因祸得福,之前看一些文章讲wasm backend在启用SIMD+multi threads后,性能要优于webgl backend,以及后续webgpu会逐步取代webgl,所以一直没太关注webgl
但这次在整合Next.js时,我发现无法启用wasm backend的SIMD+multi threads,原因是根据 tf official readme for JS Minification 这一节的说明:在基于bundlers系统(webpack)打包压缩时,需要将terserPlugin中的typeofs compress option关闭,才能启用SIMD+multi threads,不然会报错(实际过程中我也遇到了)
但尴尬的是Next.js目前还不支持自定义terser option,详情: Feature Request: Support for custom terser options,所以这次就使用了webgl backend,结果比预想要好的多(测试数据稍后附上)
2.针对 webgl backend 的内存管理
在启用 webgl backend后,尝试运行,发现有内存泄露,浏览器给出了warning:High memory usage in GPU: 1029.91 MB, most likely due to a memory leak,查询tf官方文档得知对于webgl backend需要手动管理内存
在模型推理过程中,GPU memory中存放着tensor数据,可以通过tf.memory()来查看具体的tensor数量:
1 | console.log("numTensors: " + tf.memory().numTensors); |
我分别打印了推理中和推理后的tensor数量(如下图),可以看到都在不断增长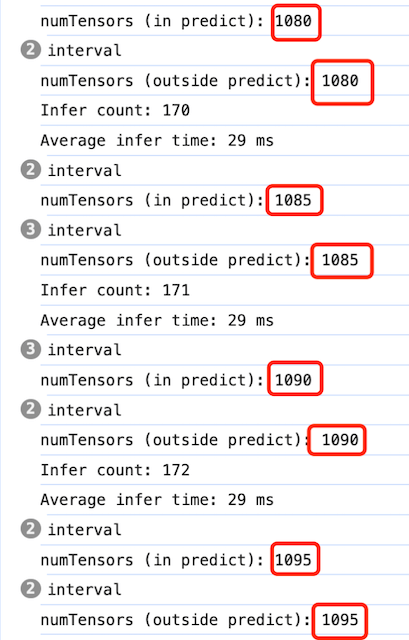
tf官方提供了多种内存清理的方法,这里我用到的是tf.tidy和tf.dispose
(1)tf.tidy
针对同步代码中创建的tensor,使用tf.tidy包裹后,它会自动做清理
1 | return tf.tidy(() => { |
这里存在的问题是:被tf.tidy包裹的代码,只能返回同步数据(如下图)
而同步数据在推理过程中,势必存在性能问题,虽然tensor数量被控制住了,但是浏览器给出了warning(如下图),提示使用async api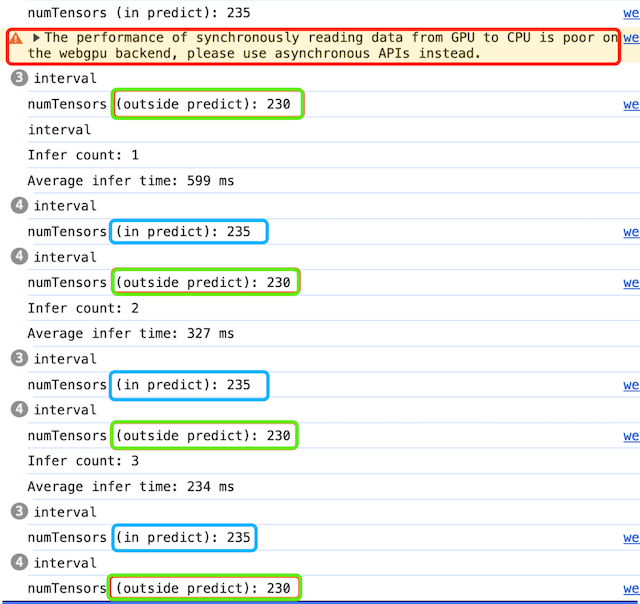
那如何针对异步数据,进行内存清理?这里可以结合使用tf.dispose
(2)tf.tidy + tf.dispose
核心代码如下:
1 | // 推理中优化 |
1 | // 推理后优化 |
推理中,使用tf.tidy包裹同步代码自动清理,推理后,使用tf.dispose手动清理,这样即保证了异步性能,又控制住了GPU内存(如下图)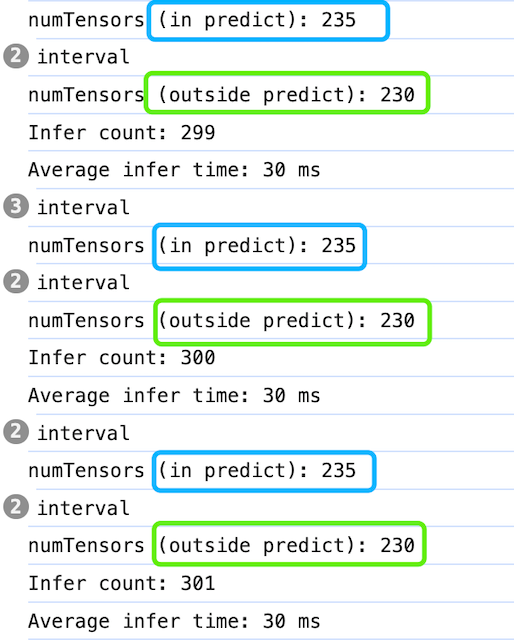
四、针对 webgl backend 的模型warm up
测试中遇到的另一个问题是,在推理开始时,会有短暂的几秒延迟,之前使用webgpu并没有这样的现象,查询tf官方文档后得知webgl需要做model warm up(如下图)
warm up就是让模型“热热身”,再开始正式推理,实现代码如下:
1 | function warmupModel(model: tf.GraphModel) { |
五、基于 webgl backend 的推理速度对比
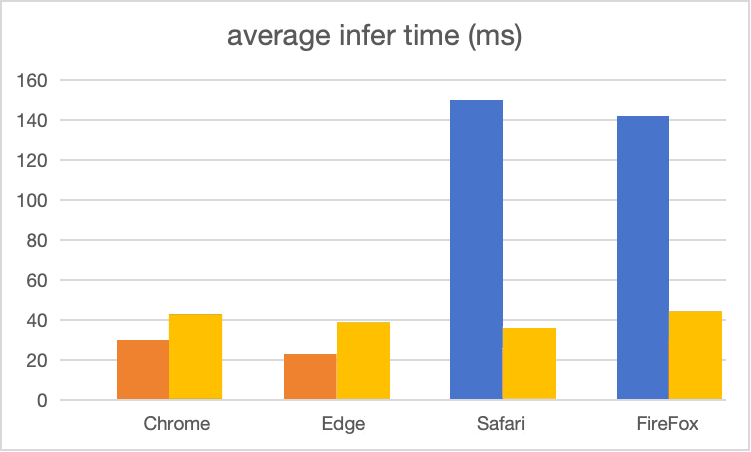
这次也顺带在PC和mobile上,测了下webgl backend的推理速度,结合之前webgpu和wasm的测试数据,汇总如下:
PC端: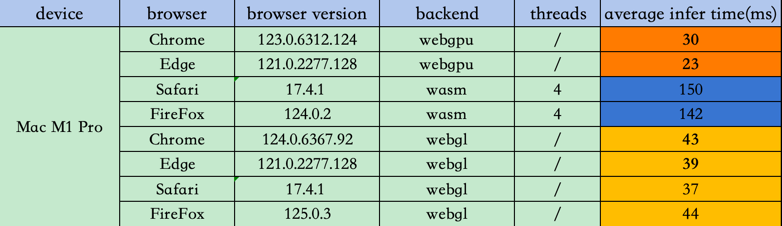
mobile端: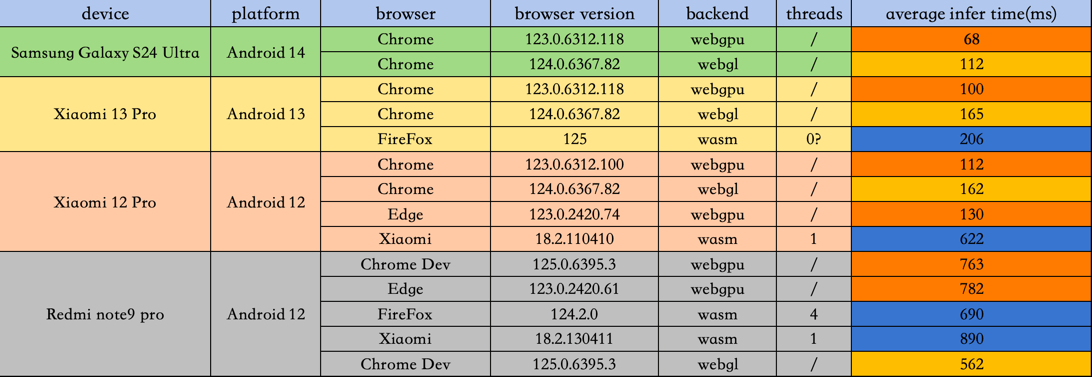
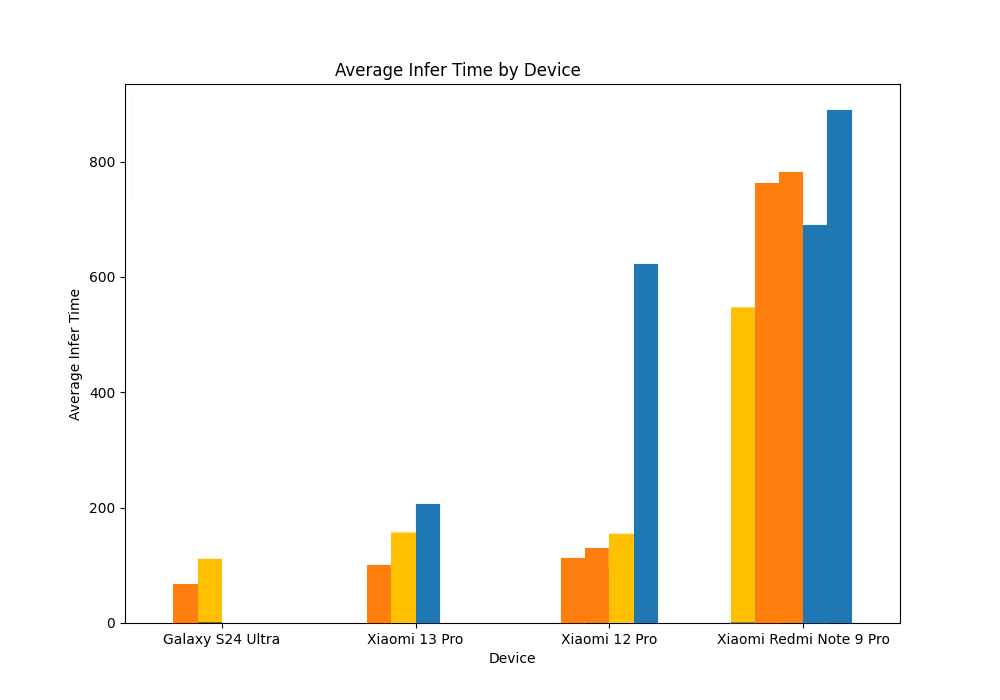
总体感觉就是:比wasm有优势,和webgpu差距其实并不大,在某些低端设备上还更快,而且考虑到浏览器兼容性,webgl会是更好的选择
六、小结
在将Tensorflow.js和Next.js整合与优化后,整体Web ML框架更趋完善合理,同时也为后续在web端构建AI原生应用提供了便利;另外也看到了webgl的优势,在webgpu还没普及开之前,它也是一种理想的选择。
完整代码:这里
演示地址:Next Web ML
版权声明:本文为博主原创文章,转载请注明作者和出处
作者:CV肉饼王
链接:https://roubin.me/web-model-load-infer-optimization-summary/
参考文章:
Object detection in the image using TensorFlow in NextJS
Hand pose detection with TensorFlow.js and Next.js
Client-Side AI with Transformers.Js, Next.js, and Web Worker Threads