1.数据从哪里来?如何构建数据集?
1 | 1.现场自行采集(成本比较高) |
2.数据量多大?
1 | 深度学习越多越好 |
3.数据量不够如何处理?
1 | 数据增强 |
4.采用的模型是什么?为什么使用YOLOv8?
1 | 效果 |
5.什么情况下使用OpenCV,什么情况下使用深度学习?
1 | Opencv:不需要程序理解图像的场景和内容,图像相对单一,干扰因素较少,需求比较简单,数据量比较少 |
6.准确率是多少?
1 | 工业中至少要95%以上,越高越好,不要过拟合 |
7.写项目经验注意的问题
1 | 项目背景(需求):用户是谁?用在什么地方?解决什么问题? |
8.什么是有监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)?请举例说明每种类型的应用场景
1 | 有监督:训练数据集包含了标签,在训练过程中,模型学习输入与标签之间的映射关系 |
9.贝叶斯公式及推导过程,有哪些应用场景?
1 | 公式:P(A|B) = P(B|A)⋅P(A) / P(B) |
10.什么是似然?
1 | 概念:在已知某些数据的情况下,模型参数取特定值的概率 |
11.什么是欠拟合、过拟合?如何避免过拟合?如何避免欠拟合?
1 | 欠拟合:指模型无法从训练数据中学习到足够的模式,导致其在训练集和测试集上都表现不佳 |
12.神经网络加速训练方法有哪些?
1 | 硬件:多GPU、分布式训练 |
13.目标检测常用算法有哪些,简述对算法的理解
1 | 两阶段检测 |
14.什么是感受野?
1 | CNN的feature map上的像素点,在原始图像上对应的区域大小 |
15.什么是正则化?L1、L2、smooth L1正则化的区别
正则化:在损失函数后面添加一个范数(惩罚项),整体上压缩了参数的大小,来防止过拟合的手段
范数表达式如下:
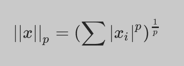
1 | L1正则化:也称为Lasso正则化,当p=1时,是L1范数,表示某个向量中所有元素绝对值之和 |
16.Loss Function、Cost Function 和 Objective Function 的区别
1 | 损失函数(Loss Function)通常是针对单个训练样本而言,给定一个模型输出y'和一个真实值y,损失函数输出一个实值损失 L = f(y,y') |
17.什么是特征归一化?为什么要归一化?
1 | 归一化一般是将数据映射到指定的范围([0, 1] 或 [-1, 1]),从而消除不同特征量纲的影响。 |
18.归一化常用方法?
1 | Min-Max Normalization |
19.归一化处理适用模型
1 | 应用归一化的模型:在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。 |
20.什么是标准化?常用方法?
1 | 标准化是将特征值调整为均值为0,标准差为1的标准正态分布 |
21.标准化和归一化的联系和区别
1 | 联系: |
22.均值、离差、离差方、方差、标准差之间的关系
1 | import numpy as np |
23.方差和标准差有什么区别?
1 | 方差和标准差都可以用来衡量数据的离散程度 |
24.回归问题的模型评估指标
1 | 1.均方误差(Mean Squared Error, MSE) |
25.分类问题中的TP、FP、TN、FN是什么
1 | TP:True Positive,正确得预测为正样本,实际就是正样本,即正样本被正确识别的数量 |
26.如何查看混淆矩阵
假设A为正样本:
| Real A | Real B | |
|---|---|---|
| Predict A | 10(TP) | 20(FP) |
| Predict B | 30(FN) | 5(TN) |
1 | 该类的预测总数:某一行的和 |
27.分类问题的模型评估指标
1 | 注意:每个类别都有自己的查准率、召回率、f1得分 |
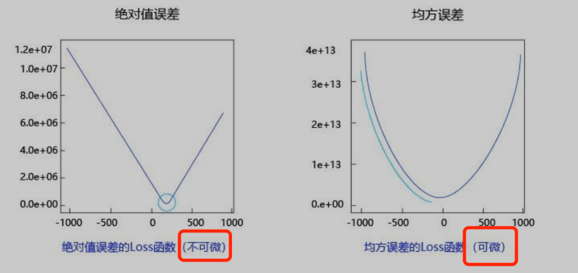
28.回归问题的损失函数,为何使用平方(MSE)而不是绝对值(MAE)?
1 | 因为MSE函数是可微的,而MAE函数不可微,具体的: |
29.损失函数和评估函数(指标)的区别?
1 | 损失函数作用于训练集,为梯度下降提供方向,用来训练模型参数 |
30.什么是超参数?有哪些常用的超参数调优手段?
1 | 超参数是在训练之前,人为预习设定的参数,而不是在训练中获得的参数 |
31.有哪些常见的超参数?各自对模型有怎样的影响?
1 | 1.学习率(Learning Rate) |
32. 什么是置信概率?
1 | 置信概率指模型对某个预测结果的确信程度,通常,分类模型(如逻辑回归、神经网络、随机森林等)在进行预测时,不仅给出一个类别标签,还会输出每个类别的置信概率。 |
33.什么是交叉验证?它有哪些常见类型?
1 | 交叉验证(Cross-Validation)是一种模型性能评估技术,在样本数量较少的情况下,它将数据集分成多份,每份轮流作为测试集,剩下部分作为训练集,通过这种方式,可以多次评估模型,每次的评估结果综合起来给出模型的总体性能 |
34.对于类别不均衡问题,有哪些处理方法?
1 | 数据层面: |
35.神经网络权重初始值如何设置?
1 | 1.不能使用零初始化 |
36.什么是线性回归?线性回归的特点是什么?
1 | 定义:用于分析两个或多个变量之间的关系的机器学习方法。它通过拟合一条直线来表示自变量和因变量之间的线性关系 |
37.什么是多项式回归?多项式回归的特点是什么?
1 | 定义:多项式回归是一种扩展的线性回归模型,用于处理自变量与因变量之间的非线性关系。虽然模型仍然是线性模型(因为参数是线性的),但它引入了自变量的多项式来捕捉更复杂的模式 |
38.什么是决策树?工作原理是什么?特点?
1 | 定义:通过树形结构来表示决策过程,每个节点表示一个属性,每个分支表示一个属性值,叶节点表示一个类或决策结果 |
39.有哪些常见的决策树算法?
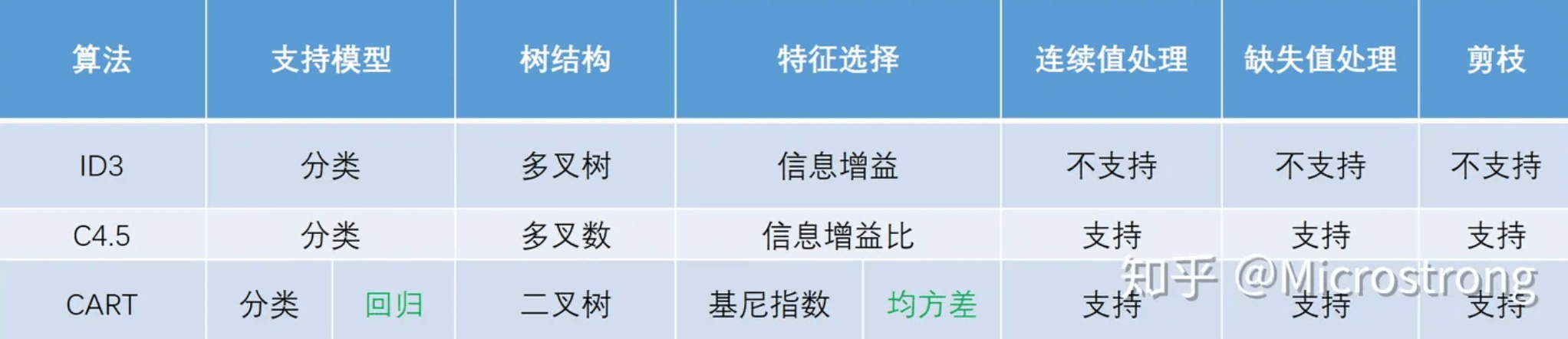
1 | ID3:基于信息增益来选择分裂属性(每步选择信息增益最大的属性作为分裂节点,树可能是多叉的)。 |
40.CART 在分类问题和回归问题中的异同
1 | 相同: |
41.什么是集成学习?
1 | 集成学习就是组合多个弱监督模型,以期望得到一个更好的强监督模型。集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他分类器也可以将错误纠正回来 |
42.Bagging与Boosting的原理是什么?二者有何区别?
1 | Bagging: 利用bootstrap方法从整体数据集中采取有放回抽样得到N个数据集,在每个数据集上学习出一个模型,最后的预测结果利用N个模型的输出得到;具体地:分类问题采用N个模型预测投票的方式,回归问题采用N个模型预测平均的方式。通过随机抽取数据的方式减少了可能的数据干扰,因此Bagging模型具有低方差 |
43.机器学习模型的偏差和方差是什么?
1 | 偏差:评判的是机器学习模型的准确度,偏差越小,模型越准确。它度量了算法的预测与真实结果的离散程度,刻画了学习算法本身的拟合能力。也就是每次打靶都比较准,比较靠近靶心。 |
44.什么是基于决策树的集合算法(集成学习)?
1 | 基于决策树构建的Bagging或Boosting类模型。 |
45.简要介绍AdaBoost、GBDT、XGBoost
1 | AdaBoost: 它通过对多个弱分类器进行加权组合来提高最终分类器的性能,具体的:在每一轮迭代中,样本的权重会根据前一轮的分类结果进行调整。分类错误的样本权重会增加,分类正确的样本权重会减小,以使后续的分类器更关注前一轮分类错误的样本 |
46.什么是随机森林?
1 | RF是一种集成学习算法,在以决策树作为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中加入了随机属性的选择,由此,随机森林的基学习器的“多样性”不仅来自样本的扰动,还来自属性的扰动,使得最终集成的泛化能力进一步增强 |
47.什么是逻辑回归?它是如何实现二分类的?
1 | 逻辑回归是一种广义的线性回归,其原理是利用线性模型根据输入计算输出,然后在逻辑函数(sigmoid)和阈值作用下,将连续值转换为两个离散值(0或1),从而实现二分类 |
48.什么是逻辑函数(sigmoid)?它有什么特点?
1 | sigmoid函数能将(−∞,+∞)的值映射到(0,1)之间,通过选取合适的阈值转换为两个 |
49.什么是信息熵?
1 | 信息熵(information entropy)是度量样本集合纯度的常用指标,该值越大,表示该集合纯度越低(或越混乱),该值越小,表示该集合纯度越高(或越有序) |
50.什么是交叉熵损失函数?
1 | 交叉熵(Cross Entropy Loss)是一种在机器学习和深度学习中广泛使用的损失函数,主要用来衡量真实概率与预测概率之间的差异 |
51.什么是朴素贝叶斯分类?特点是什么?何时使用?
1 | 朴素贝叶斯分类(Naive Bayes Classifier)是一种基于贝叶斯定理的概率分类方法。它假设特征之间是相互独立的,这一假设称为“朴素”假设。 |
52.常见的朴素贝叶斯分类器有哪些?
1 | 高斯朴素贝叶斯(Gaussian Naive Bayes):假设特征服从高斯分布,常用于连续数据 |
53.什么是支持向量机?
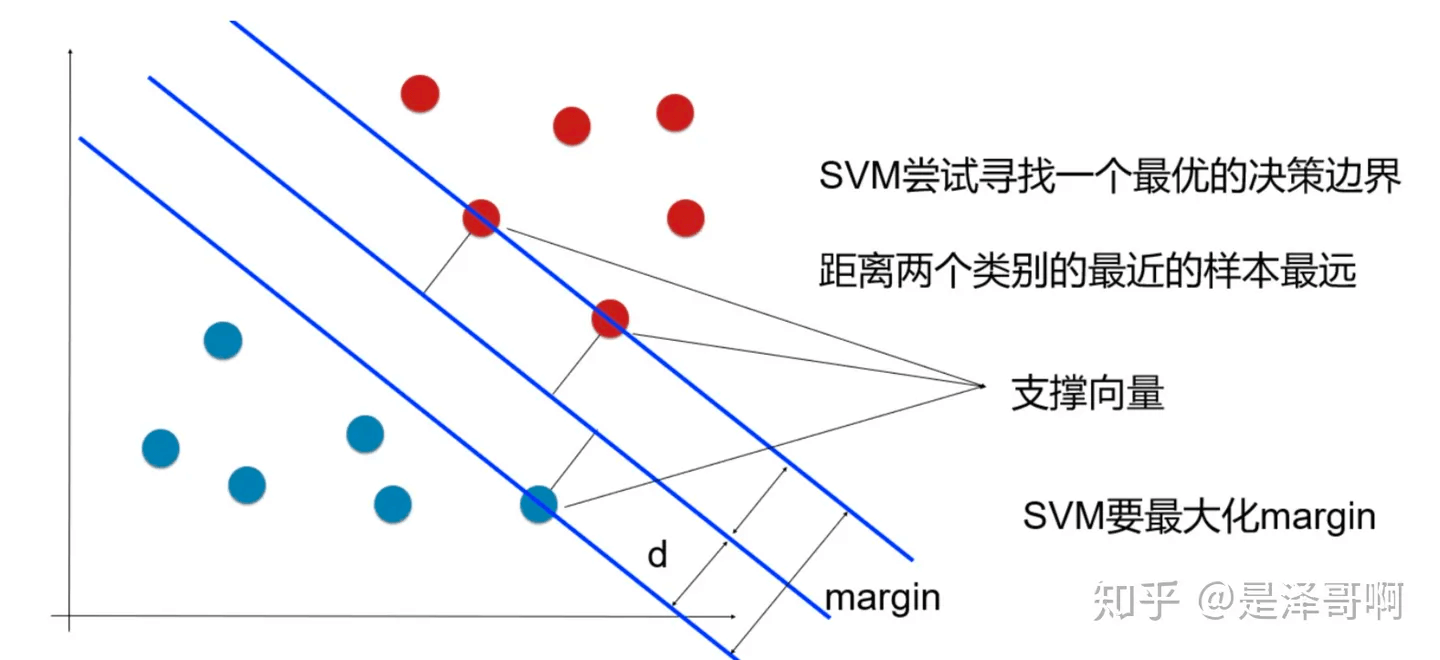
1 | 支持向量机(Support Vector Machine, SVM)是一种用于分类和回归的监督学习模型。它的基本思想是找到一个能够最大程度分离不同类别数据的超平面 |
54.SVM寻找最优边界要求有哪些?
1 | (1)正确性:对大部分样本都可以正确划分类别; |
55.SVM的工作原理?
1 | 线性可分情况:如果数据可以用一个直线(或超平面)完全分开,SVM会找到那个使得两个类别之间的间隔最大的超平面 |
56.SVM中的核函数是什么?常用的核函数有哪些?
1 | 主要作用是将原始特征空间中的数据映射到一个更高维的空间,使得在这个高维空间中,数据线性可分 |
57.SVM的特点?
1 | 优点: |
58.什么是聚类?
1 | 聚类是一种无监督学习方法,根据数据集中样本相似性,将它们分到不同的簇中,同一个簇中的样本之间相似度较高,不同簇之间的样本相似度较低 |
59.有哪些常用的相似度度量方式?
1 | 1.欧氏距离(Euclidean Distance):L2距离 |
60.聚类问题的评价指标是什么?
1 | 轮廓系数(Silhouette Coefficient):综合考虑簇内紧密程度和簇间分离程度来衡量聚类效果,取值[-1,1],越接近1越好 |
61.什么是K-Means聚类?
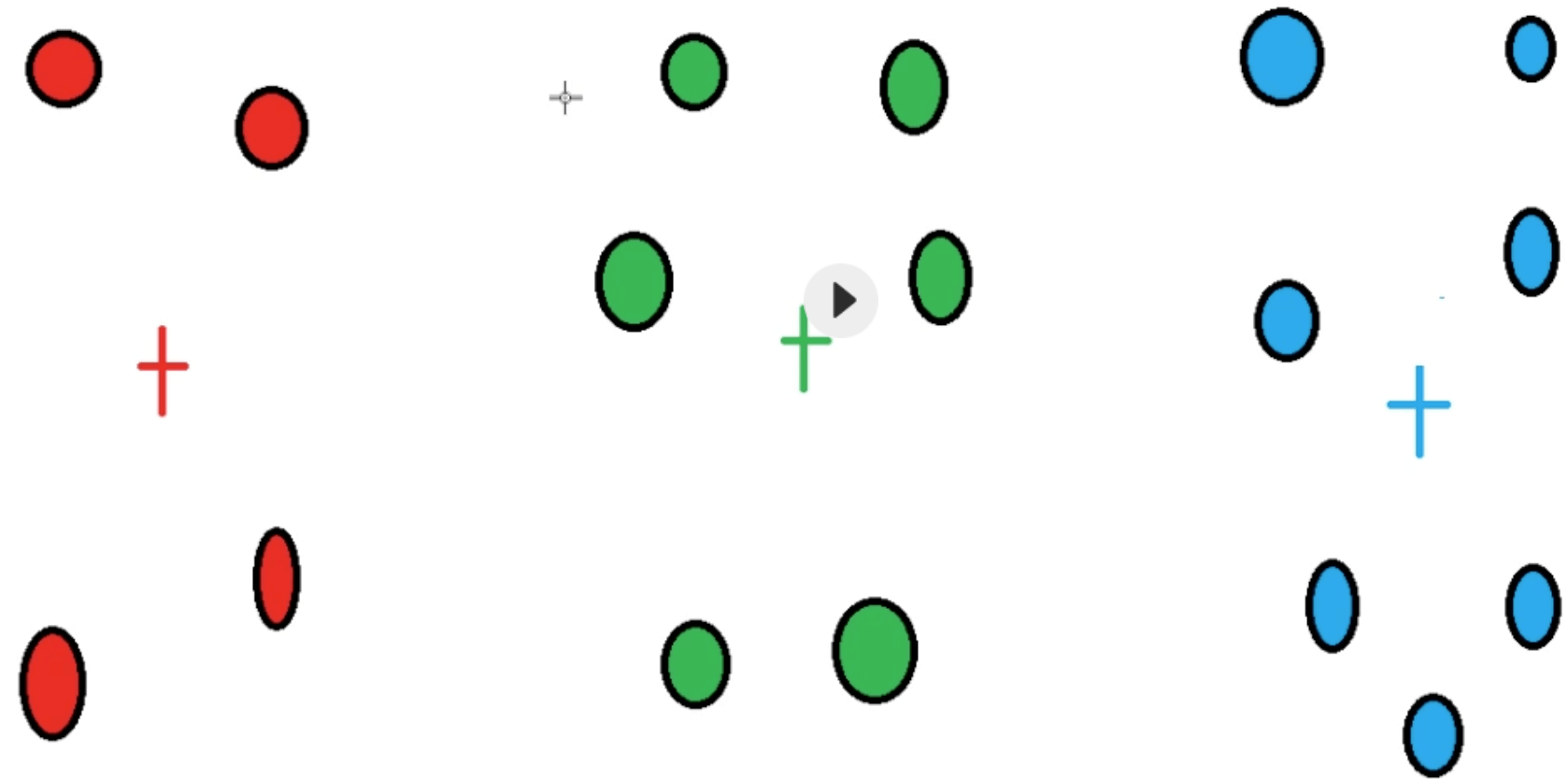
1 | K-Means聚类是一种基于原型的聚类算法,通过迭代的方式,将每个数据点分配到K个预定义的簇中,目标是最小化每个簇内点与簇中心的距离之和 |
62.什么是DBSCAN(噪声密度)?
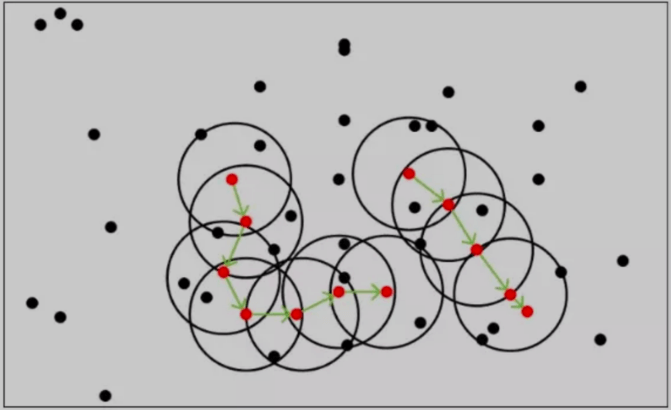
1 | DBSCAN是一种基于密度的聚类算法,用于发现数据中的簇和噪声。DBSCAN与K-Means不同,不需要预先指定簇的数量,并且能够有效处理噪声点 |
63.什么是凝聚层次算法?
1 | 凝聚层次算法(Agglomerative Clustering)是一种基于层次的聚类方法,主要用于数据点或簇的逐步合并,以形成层次结构。其核心思想是从每个数据点作为一个独立的簇开始,然后逐步合并最相似的簇,直到满足某种终止条件,如达到预设的簇数量或所有数据点都在同一个簇中 |
64.什么是神经网络?它有哪些常见类型?
1 | 神经网络是一种模拟生物大脑结构和功能的机器学习技术,它由多个人工神经元组成,可以学习复杂的模式并作出预测 |
65.神经网络中的权重和偏置是什么?
1 | 权重:控制输入信号重要性 |
66.深度学习的优缺点是什么?
1 | 优点: |
67.什么是激活函数?为什么要使用激活函数?
1 | 在神经网络中,将输入信号的总和转换为输出信号的函数被称为激活函数(activation function) |
68.神经网络中常用的激活函数有哪些,各自有什么特点?
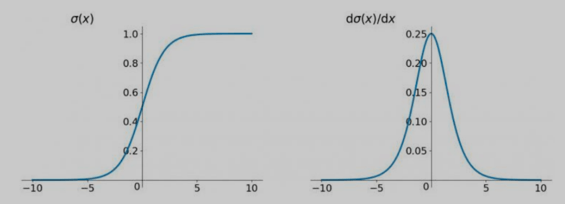
1 | 1.sigmoid: 又叫逻辑(Logistic)函数,能将(-∞, +∞)的数值映射到(0, 1)的区间,可以用来做二分类 |
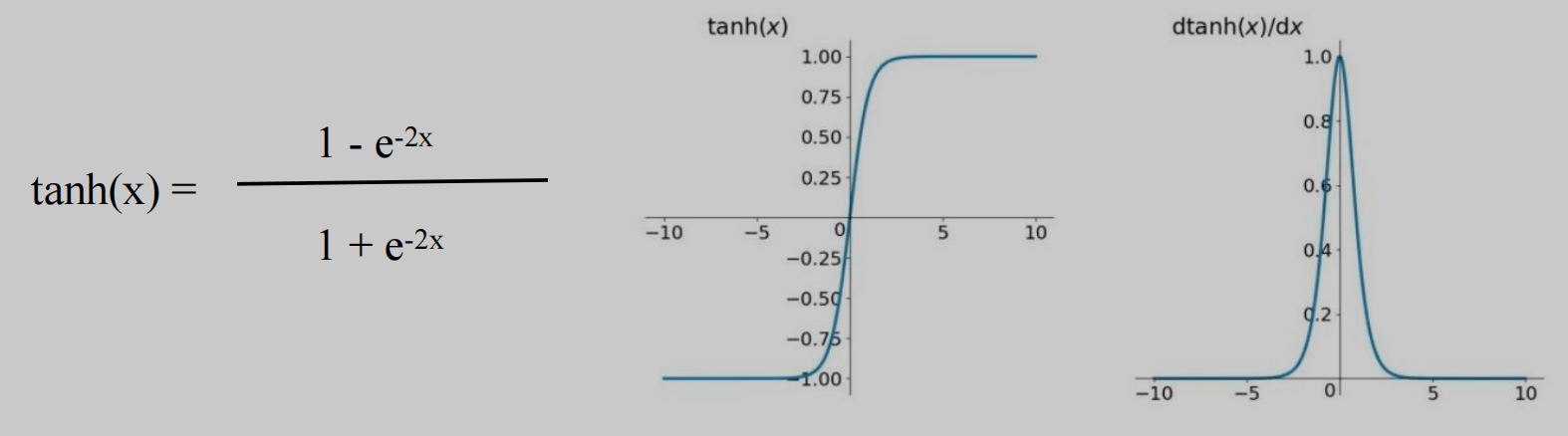
1 | 2.tanh: 双曲正切函数 |
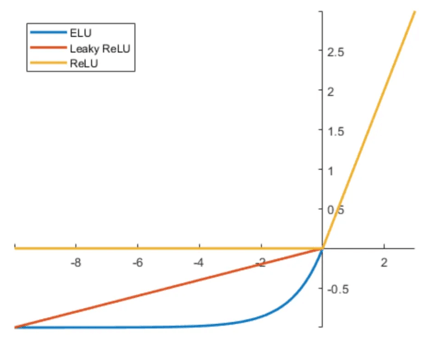
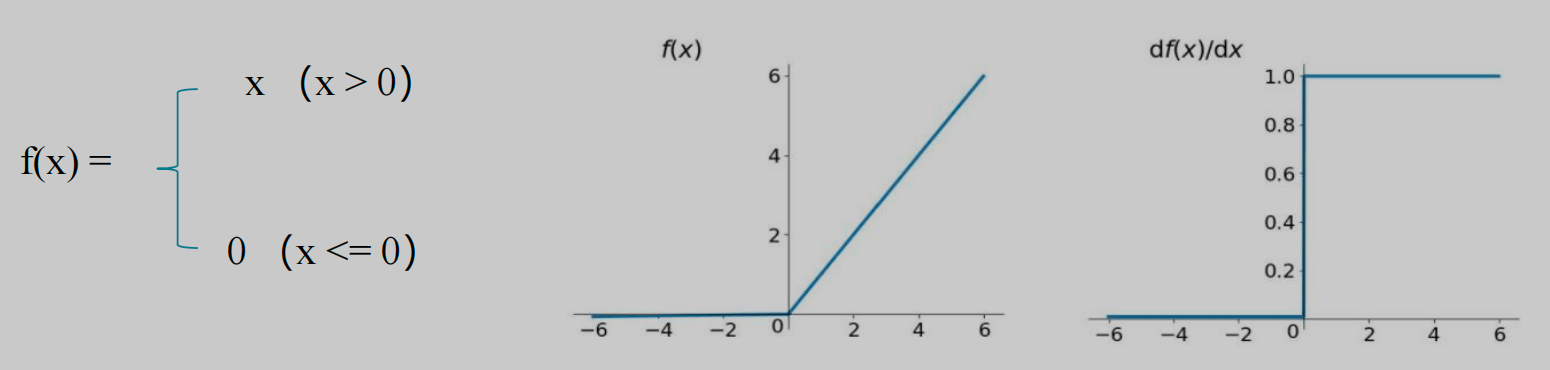
1 | 3.relu: Rectified Linear Units,修正线性单元, |
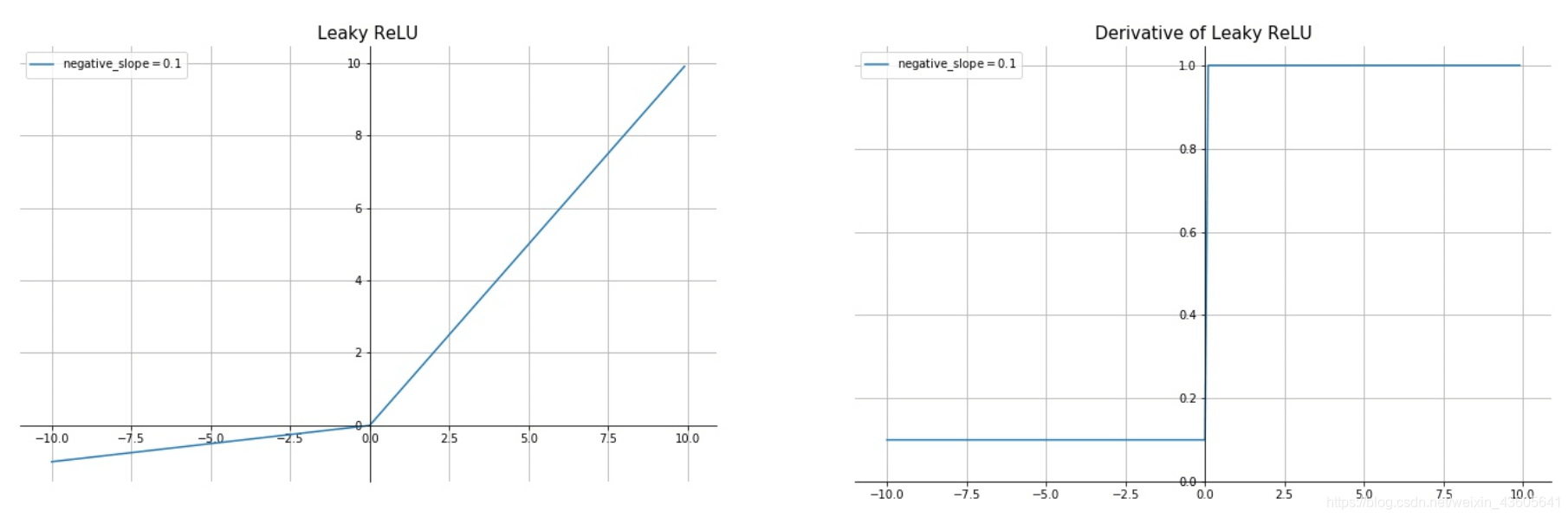
1 | 4.Leaky ReLU |
1 | 5.ELU |
1 | 6.softmax |
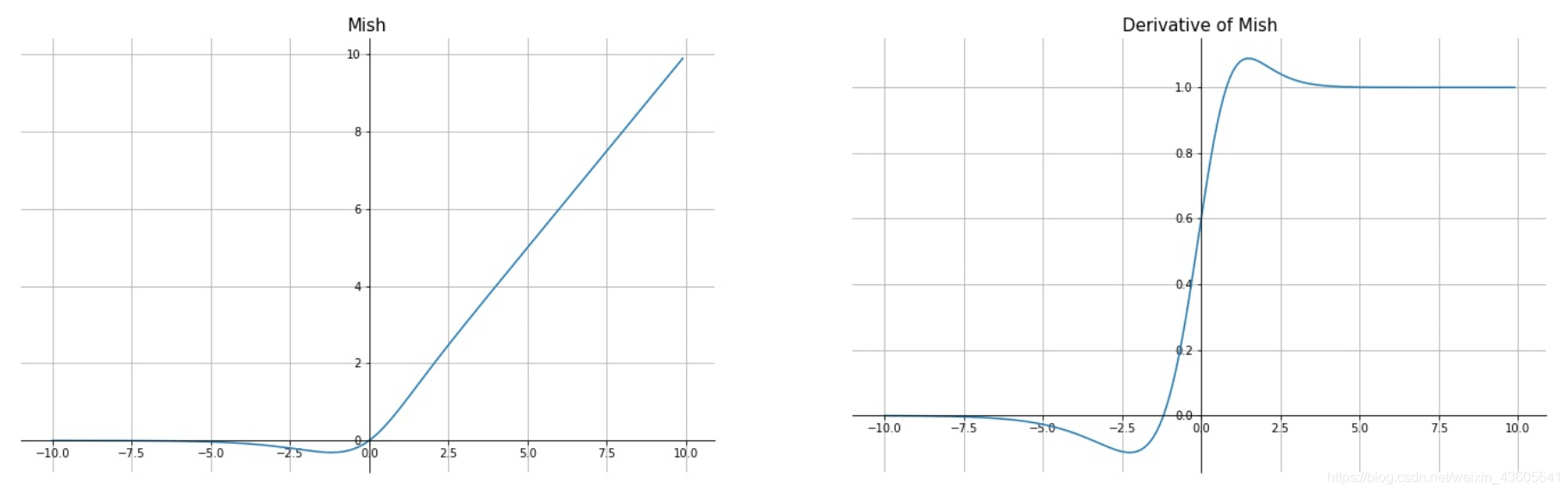
1 | 7.Mish |
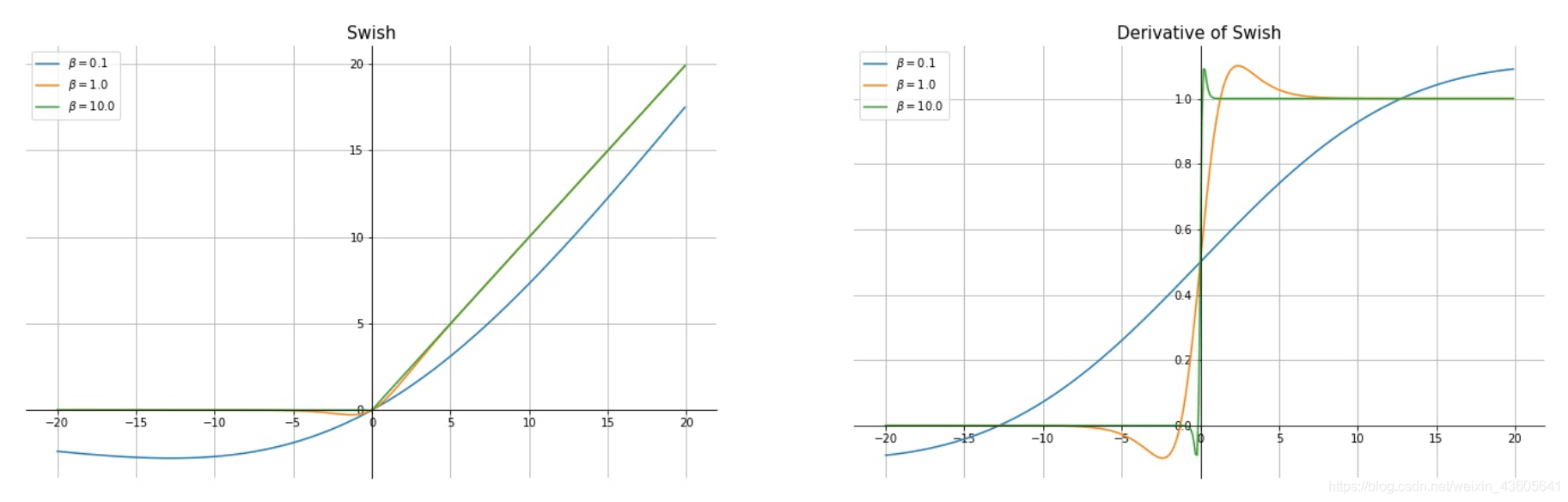
1 | 8.Swish |
69.激活函数的比较
1 | 1)Sigmoid和RELU: Sigmoid容易出现梯度消失, RELU修正了梯度消失的问题 |
70.什么是损失函数?损失函数的作用是什么?
1 | 损失函数(Loss Function),又称代价函数(Cost Function),用来度量预测值和实际值之间的差异,在模型训练中,为梯度下降更新参数指明方向 |
71.什么是梯度?什么是梯度下降?
1 | 梯度是一个向量,它表示一个函数在某一点的方向导数。简单来说,梯度告诉我们函数在某一点的增长最快的方向 |
72.什么是梯度消失?如何解决梯度消失问题?
1 | 梯度消失问题指的是在反向传播过程中,梯度在层与层之间逐渐变小,最终导致靠近输入层的隐层的权重更新非常缓慢甚至几乎不更新,使得模型难以学习到数据特征 |
73.什么是梯度爆炸?如何解决梯度爆炸问题?
1 | 梯度爆炸是指在神经网络训练过程中,梯度在反向传播的过程中不断累积,导致梯度值变得非常大,从而使权重更新幅度过大,导致网络训练不稳定,甚至无法收敛 |
74.什么是反向传播算法?为何要使用?
1 | 反向传播(Backpropagation algorithm)全称“误差反向传播”,是在深度神经网络中,根据输出层输出值,来反向调整隐层权重的一种方法 |
75.深度学习中,常见的优化器(梯度下降算法)有哪些?各有什么特点?
1 | 1.随机梯度下降(SGD):每次随机使用一个样本来计算梯度和更新权重。优点是计算快,缺点是收敛速度慢 |
76.CNN中的feature map、padding、stride分别是什么?
1 | feature map:特征图,即经过卷积操作后输出的图像数据 |
77.卷积运算输出矩阵大小的计算公式?
1 | OH = (H + 2P - FH) / S + 1 |
78.CNN网络中的卷积层、激活层、池化层各有什么作用?
1 | 卷积层(Convolutional Layer):降维和提取特征 |
79.什么是最大池化、平均池化?
1 | 最大池化(Max Pooling):选取图像区域的最大值作为池化后的值,有助于提取关键信息 |
80.池化层有什么特点?
1 | 1)没有要学习的参数 |
81.深度卷积网络中的降采样,有哪些方式?
1 | 1.stride大于1的pooling |
82.什么是dropout?为什么dropout能避免过拟合?
1 | 在神经网络训练过程中,根据设置的比例,随机忽略一部分神经元,可以有效防止过拟合,还能提升模型精度 |
83.什么是批量归一化(Batch Normalization),其优点是什么?
1 | 以进行学习时的mini-batch为单位,按mini-batch进行归一化。具体而言,就是使mini-batch的数据分布的均值为0、标准差为1 |
84.什么是分词?分词的作用是什么?
1 | 分词(Word Segmentation)指的是将一段连续的文本按照一定的标准切分成一个一个的词汇。 |
85.中文分词有哪些方法?
1 | 一、基于规则的方法 |
86.什么是词性标记?
1 | 词性标记(Part-Of-Speech tagging, POS tagging)是将单词分配到各自对应词性的任务。 |
87.什么是词干提取?
1 | 词干提取(stemming)是抽取词的词干或词根形式, |
88.什么是词袋模型?它的缺点是什么?
1 | 词袋模型(Bag-of-words model,BoW)是一种文本表示方法,它将文本转换为词的集合(袋子),忽略词的顺序和语法关系,只关心词的出现频率 |
89.什么是TF-IDF?
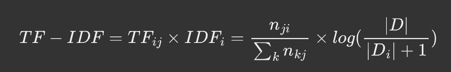
1 | TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种文本分析和信息检索技术,常用于评估一个文档集中一个词对某份文档的重要程度,核心思想是,如果一个词在一篇文档中频繁出现,而在其他文档中很少出现,那么这个词对这篇文档具有较高的重要性 |
90.常用的文本表示方法有哪些?各自特点是什么?
1 | 一、离散表示方法 |
91.什么是语料库?它的特点、作用是什么?
1 | 语料库(corpus)是指存放语言材料的仓库。现代的语料库是指存放在计算机里的原始语料文本、或经过加工后带有语言学信息标注的语料文本 |
92.什么是Word2vec?代表模型有哪些?
1 | Word2vec是一种词嵌入技术,通过将单词转换为向量形式,使得词与词之间可以定量地度量它们之间的关系 |
93.Word2vec中的负采样是什么?
1 | 负采样(Negative Sampling)是Word2vec中的一种优化技术,用于加速模型的训练过程。其主要目标是简化Softmax函数的计算,将多分类转变为二分类,从而提升训练效率 |
94.常用的色彩空间有哪些?
1 | 1.RGB |
95.什么是图像灰度化处理?具体步骤是怎样的?
1 | 图像灰度化处理是将彩色图像转换为灰度图像的过程。彩色图像通常使用RGB模型,每个像素由这三种颜色的不同强度组合而成。而灰度图像中,每个像素只包含一个表示亮度的值(0 ~ 255) |
96.什么是图像二值化/反二值化处理,有什么优点?
1 | 图像二值化处理是将灰度图像或彩色图像转换为只有黑白两种颜色(即二值)的图像的过程 |
97.什么是直方图均衡化?
1 | 直方图均衡化是一种图像处理技术,用于改善图像的对比度。通过调整图像像素的灰度值,使得输出图像的灰度直方图尽可能均匀分布,从而增强图像的细节和对比度 |
98.图像加法运算有什么应用?
1 | 图像合成:例如,图像水印可以通过加法叠加到原始图像上 |
99.图像减法运算有什么应用?
1 | 运动检测:通过对连续帧进行减法运算,可以检测出前后帧之间的差异,从而识别出运动物体 |
100.图像放大时,可以采用哪些插值法?
1 | 1.最近邻插值(Nearest Neighbor Interpolation) |
101.对图像进行模糊平滑处理,可以使用哪些方式?
1 | 1.均值模糊 :通过用邻域内所有像素的平均值替换中心像素来进行平滑 |
102.对图像进行边沿检测,有哪些常用算子?
1 | 1.Sobel算子:基于一阶导数,简单高效 |
103.图像的腐蚀有哪些实际的应用场景?
1 | 定义:沿着边界向内收缩 |
104.图像的膨胀有哪些实际的应用场景?

1 | 定义:向外扩充 |
105.图像的开运算有哪些实际的应用场景?

1 | 定义:先腐蚀,后膨胀 |
106.图像的闭运算有哪些实际的应用场景?
1 | 定义:先膨胀,后腐蚀 |
107.图像的形态学梯度运算是什么?

1 | 定义:膨胀图像减去腐蚀图像 |
108.什么是图像的礼帽运算?

1 | 主要用于突出图像中的亮细节或暗细节 |
109.在深度学习模型训练中,收敛速度和训练速度分别是什么?
1 | 收敛速度:指模型训练达到收敛状态所需的时间。收敛状态是指模型的损失函数不再发生显著变化,或者达到预先设定的终止条件 |
110.在模型训练过程中,为何增加batch size可能会导致模型的收敛速度变快?
1 | batch size 越大,梯度噪声越小,梯度下降的方向更加准确,从而加快收敛速度 |
111.在SVM、逻辑回归等二分类模型中,在模型训练完成后,如果调高分类阈值,模型的precision、recall、auc值会如何变化?
1 | precision: 提高 |
112.LSTM对比原始RNN的最大改进是什么?bi-LSTM对比LSTM最大的改进是什么?
1 | LSTM解决了梯度消失,能处理更长的序列 |
113.经过下列卷积操作后,3x3 conv -> 3x3 conv -> 2x2 max pool -> 3x3conv,卷积步长为1,没有填充,输出神经元感受野是多大?
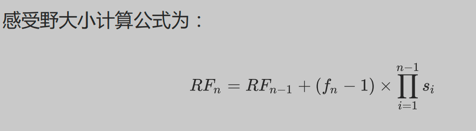
1 | 公式解释:RFn表示第n层感受野大小,fn表示第n层滤波器大小,si表示到n-1层的步长的连乘 |
114.简述离散化的好处,并写出离散化的常用方法有哪些?
1 | 好处:降维、降低噪声的影响 |
115.常见函数的求导公式

1 | y = n^x,当x<0时,y' = -n^xln(n) |
116.利用梯度下降法优化目标函数ln(wx),给定第一轮参数w=2, x=10,请写出第三轮优化后的参数值(学习率 = 0.1)
1 | 梯度下降参数更新公式:w = w - η*(▲fnloss/w) |
117.已知卷积层中输入尺寸32x32x3,有10个大小为5x5的卷积核,stride=1,pad=2,输出特征图大小为多少?总的特征数量为多少?
1 | 特征图尺寸计算公式:OH = (H + 2P - FH) / S + 1 |
118.Faster RCNN中,ROI pooling具体如何工作(怎么把不同大小的框,pooling到同样大小)?
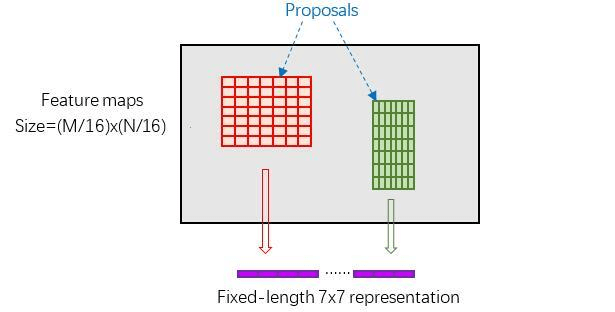
1 | 这里有3个参数:pooled_w、pooled_h和spatial_scale |
119.简述SSD和YOLO的区别?
1 | YOLO通常比SSD速度更快,但准确性略低;SSD通常比YOLO准确性更高,但速度略慢 |
120.YOLOv2与YOLOv3的区别
1 | 骨干网:YOLOv3采用Darknet53,YOLOv2采用Darknet19 |
121.测试集中有1000个样本,600个是A类,400个B类,模型预测结果700个判断为A类,其中正确有500个,300个判断为B类,其中正确有200个。请计算B类的查准率(Precision)和召回率(Recall)
1 | B为正样本,混淆矩阵如下: |
122.Sigmoid函数的导数推导过程
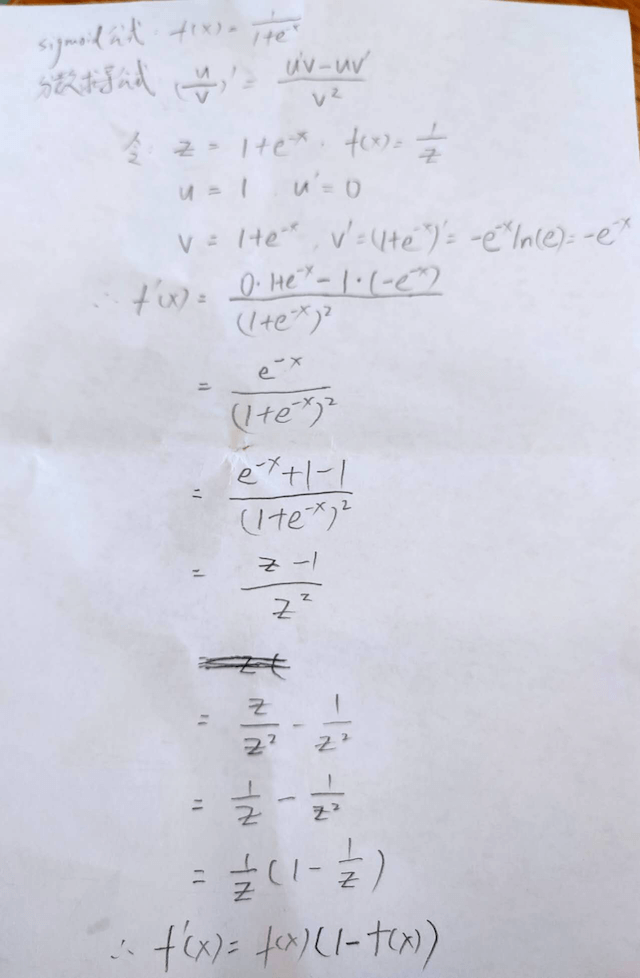
123.深度学习中,实现上采样有哪些方法?
1 | 1.插值法:最近邻、双线性 |
124.深度可分离卷积是什么?
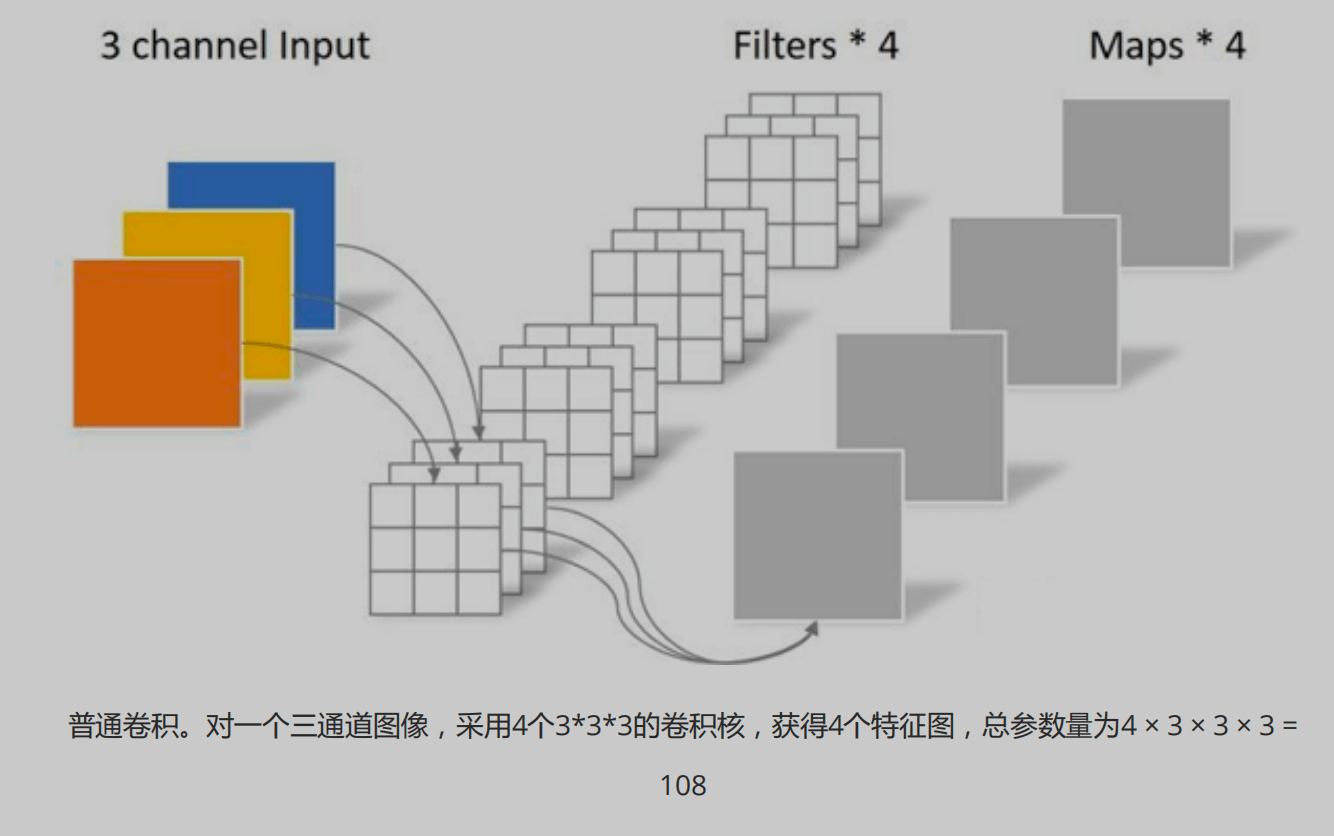
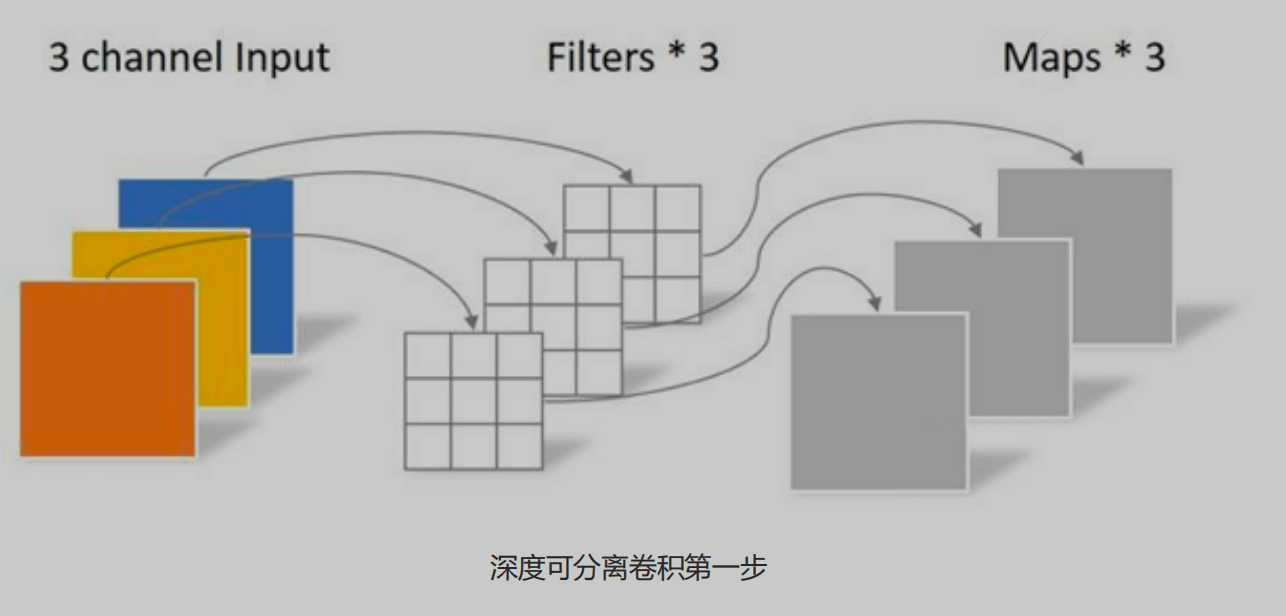
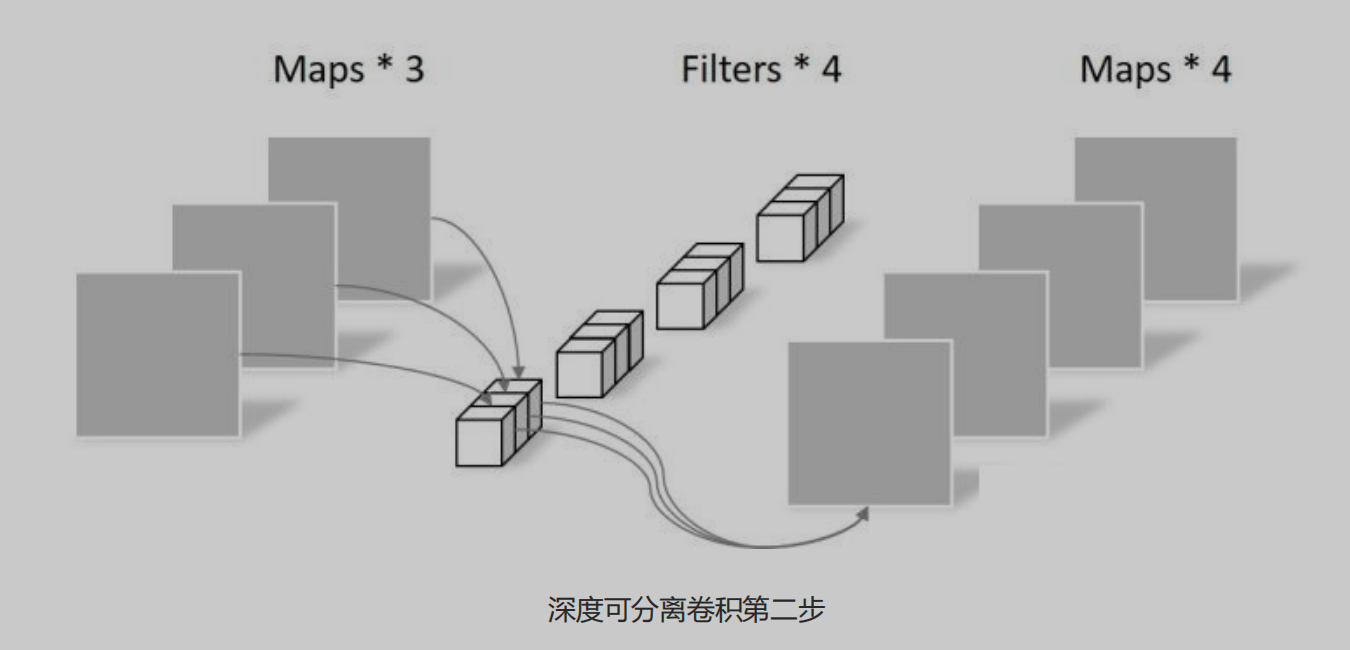
1 | 深度可分离卷积(Depthwise Separable Convolution)是一种卷积操作,它将标准卷积分解为两个独立的操作:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。这种分解能够显著减少计算量和参数量,从而提高卷积神经网络的效率,特别适合移动端设备 |
125.LSTM跟GRU的区别
1 | 1.结构:LSTM有三个门(forget,input,output),GRU只有两个门(update和reset) |
126.什么是一维傅里叶变换?它在图像分析中有哪些作用?
1 | 一维傅里叶变换(1D Fourier Transform)是一种将一维信号从时域转换到频域的数学方法。它可以将一个信号分解为不同频率的正弦波和余弦波的叠加。 |
127.常用图像分割算法有哪些?各有什么优缺点?
1 | 1.FCN:又称全卷积网络,去掉了CNN中的全连接层。对输入图像进行层层卷积、上采样,预测出每个像素所属的类别 |
128.简单介绍几种常用的人脸检测算法
1 | 基于传统人脸检测算法:Haar级联人脸检测算法 |
129.你知道哪些OCR中的文字识别模型和文字检测模型?
1 | 文字识别模型: CRNN+CTC |
130.在图像处理中,滤波、模糊、去噪,这三者是什么关系?
1 | 滤波(Filtering):是一个广泛的概念,指通过某种方式修改图像的像素值以达到特定目的,比如低通滤波可以平滑模糊图像,高通滤波可以锐化增强图像 |
131.什么是HOUGH(霍夫)变换?
1 | HOUGH(霍夫)变换是一种图像处理技术,用于检测图像中的几何形状(如直线、圆和椭圆等)。它的主要思想是通过将图像空间(通常是二维空间)中的点转换到参数空间(如极坐标空间),然后在参数空间中寻找累加器的局部最大值,这些最大值对应于图像空间中的几何形状 |
132.列出机器学习中常见的分类算法,并比较各自的特点
1 | 1.逻辑回归(Logistic Regression):通过Sigmoid函数将线性回归的结果映射到0和1之间 |
133.使用opencv将一个图像旋转180°
1 | def rotate(img, angle, center=None, scale=1.0): |
134.机器学习中的降维有哪些常用方法?
1 | 1.主成分分析(PCA):通过找到数据中最大方差的方向(主成分),将数据投影到这些方向上,从而实现降维 |
135.vgg16的网络结构?
1 | 网络结构:16层,包含13个卷积层(卷积+最大池化)和3个全连接层,输出1000个分类 |
136.ResNet的网络结构?
1 | ResNet旨在解决深层网络训练中的梯度消失问题。其核心思想是通过引入残差连接(shortcut connection)来简化网络的训练过程,使得可以训练更深的网络结构 |
137.什么是学习率的余弦退火?
1 | 定义:余弦退火(Cosine Annealing)是一种在深度学习训练过程中动态调整学习率的方法。其核心思想是通过余弦函数来降低学习率,从而帮助模型更好地收敛并避免过拟合 |
138.简述yolov8网络结构
139.用python实现iou计算
1 | def intersection(box1,box2): |
140.什么是NMS?并用python实现
1 | 预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比(IoU)最大的、去掉非最大的预测结果,这就是非极大值抑制(Non-Maximum Suppression,简写作NMS) |
1 | # NMS |
141.mAP值是如何计算的?
1 | mAP(mean Average Precision)指的是平均精度均值,是用来评估目标检测算法性能的指标。它的计算方法如下: |
142.使用pytorch训练模型的完整流程
1.create dataset
1 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu") |
2.create model
1 | model = models.resnet50(pretrained=True) |
3.train model
1 | criterion = torch.nn.MSELoss() |
4.validate model
1 | model.eval() |
5.save model
1 | torch.save(model.state_dict(), "keypoints_model.pth") |
143.什么是SIFT和HOG特征提取?
1 | SIFT(尺度不变特征变换):检测并描述图像中的局部特征点,具有尺度和旋转不变性。 |